Up until last week PL/I macros were a bit of a mystery. Most of the ones that I’d seen in customer code were impressively inscrutable, and if I had to look at any of them, my reaction was to throw my hands in the air and plead with the compiler backend guys for help. Implementing one such macro has been very helpful to understanding how these work.
Here is a C program that roughly models some PL/I code of interest
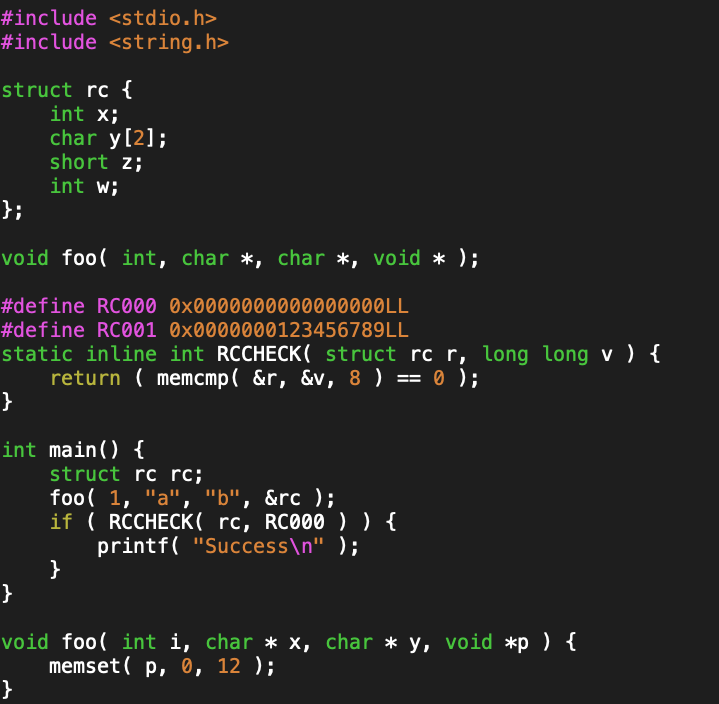
The documentation for the ‘foo’ function says of the final return code parameter that it is 12 bytes long, and that the ‘rcvalues.h’ header file has a set of RCNNN constants and a RCCHECK macro that can be used to test for any one of those constants. A possible C implementation of that header might look something like:
/* rcvalues.h */ #define RC000 0x0000000000000000LL #define RC001 0x0000000123456789LL /* ... */ #define RCCHECK( urc, crc ) ( memcmp( &(urc), &(crc), 8 ) == 0 )
PL/I APIs do not typically use modern constructs like typedefs. The closest that I have seen is for an API header file (copybook in the mainframe lingo) is to declare a variable (which becomes a local variable with a specific name in the including module), which the programmer can refer to using the LIKE keyword, as in the following example:
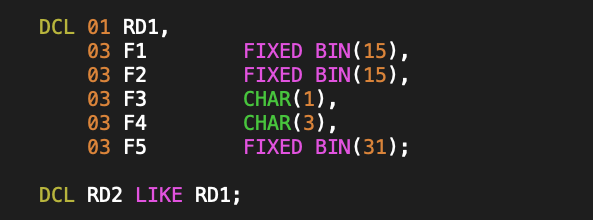
I believe there is also a DEFINE keyword available in newer PL/I compilers, which provides a typedef like mechanism, but most existing code probably doesn’t use such new-fangled nonsense, when cut and paste has far superior maintenance characteristics. For that reason, the API would be unlikely to have a typedef equivalent for the return code structure. Instead, the PL/I equivalent of the C code above, would probably look like:
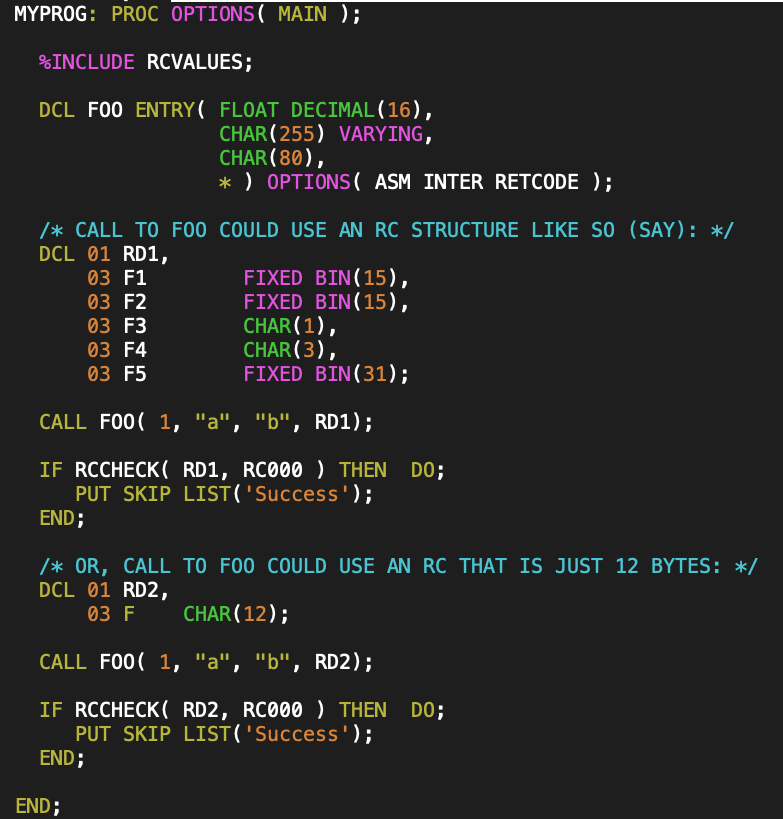
(i.e. the C code is really modeled on the PL/I code of this form, and if this was a C API, the API would have a struct declaration or a typedef for the return code structure)
The RCNNN constants would actually be found as named variables (not immutable constants) in the copy book, perhaps declared something like:

I struggled a bit to figure out what the PL/I equivalent of my C RCCHECK macro would be. The following inner function correctly did the required type casting and comparisons:
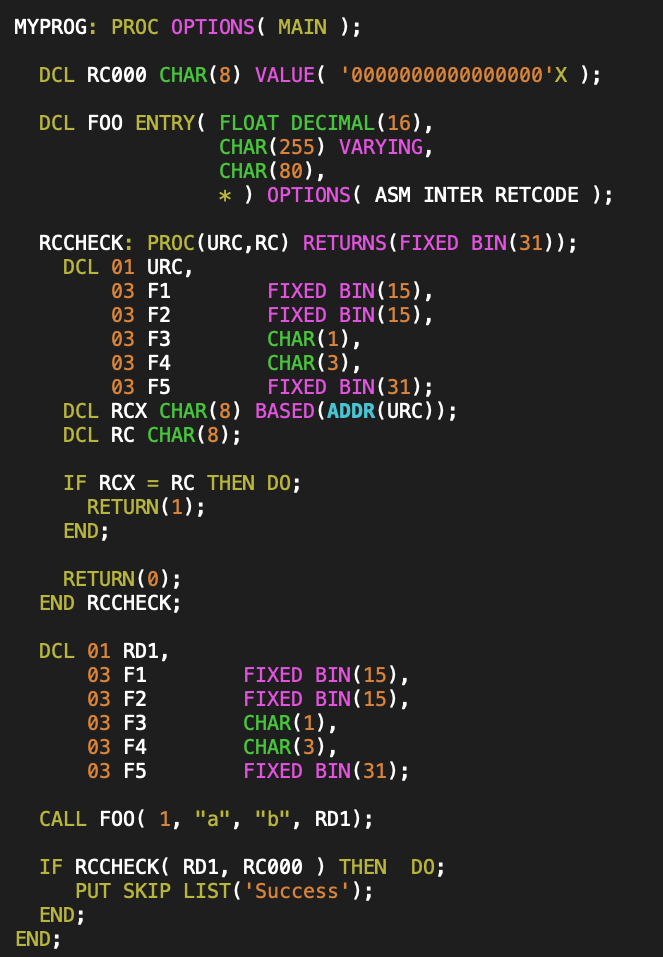
The implementation is very long, since the entire declaration of the input parameter type has to be duplicated.
If I was to put this RCCHECK implementation above into my RCVALUES.inc header file, it would only work if all the customer declaration of their return code structure objects were field by field compatible. What I really want is for my RCCHECK function to take the address of the parameter, and pass that instead of the underlying type. That was not at all obvious to figure out how to do, but with some help, I was eventually able to construct a PL/I macro (with helper inner-function) of the following form:
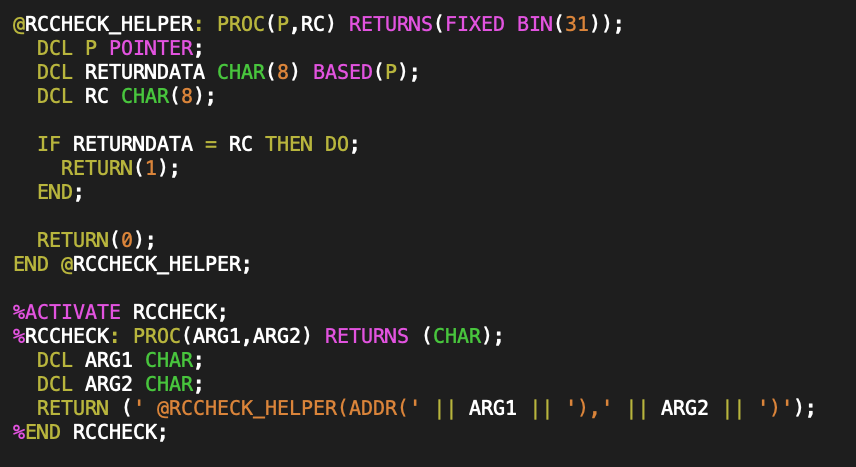
It’s clearly no longer a one liner. Some notes on this PL/I macro:
- The PL/I macro body looks like a regular PL/I function, but the begin-PROCEDURE and END statements start with % (% is not part of the PROC name.)
- Macro parameters and return values are explicit strings, regardless of the types of the parameters that were actually passed.
- In PL/I the || symbol is used for string concatenation, so this constructs output that inserts an ADDR() call around ARG1 token and then passes the ARG2 token as is.
- I don’t know if there’s a way to implement this macro in a way that doesn’t require a helper function, and still have the output work in the context of an IF statement.
- You have to explicitly enable the macro, using %ACTIVATE. In my case, without %ACTIVATE, the RCCHECK symbol ends up as an undeclared external entry, and was no call to the @RCCHECK_HELPER function \({}^{[1]}\).
- Observe that the PL/I macro provides a mechanism to jam whatever you want into the code, as the compiler’s macro preprocessor replaces the macro call tokens with the string that you have provided, leaving that string for the final compiler pass to interpret instead.
If I compile the code using this macro version of RCCHECK, the preprocessor output looks like:

I’m still pretty horrified at some of the macros that I’ve seen in customer code — they almost seem like the source equivalent of self modifying code. You can’t figure out what is going on without also looking at all the output of the precompiler passes. This is especially evil, since you can write PL/I preprocessor macros that generate preprocessor macros and require multiple preprocessor passes to produce the final desired output!
Footnotes
[1] note that @ is a valid PL/I character to use in a symbol name, as is # and $ — so if you want your functions to look like swear words, this is a language where that is possible. Something like the following is probably valid PL/I :
For added entertainment, your file names (i.e. PDS member names) can also be like ‘#@$1A#@’. Storing files with names like that on a Unix filesystem results in hours of fun, as you are then left with the task of figuring out how to properly quote file names with embedded $’s and #’s in scripts and makefiles.



{kind=link}