In toycalculator, an MLIR/LLVM compiler experiment, I described a rudimentary MLIR based compiler.
I’ve now added fixed size integer types, a boolean type and boolean constants (but not boolean operators), and two floating point types. For the time being, the untyped ‘DCL’ declaration type (FLOAT64) is still in the grammar and the parser/MLIR-builder.
There’s lots still in the TODO list, including control flow, functions and dwarf support. I was quite surprised that given the location requirements for all MLIR statements, we don’t get DWARF instrumentation for free when doing LLVM lowering, and I wonder if I am missing some sort of setup for that.
New Language/Compiler enhancements
Here are the new elements added to the language:
- Declare variables with BOOL, INT8, INT16, INT32, INT64, FLOAT32, FLOAT64 types:
- TRUE, FALSE, and floating point constants:
- An EXIT builtin to return a Unix command line value (must be the last statement in the program):
- Expression type conversions:
The type conversion rules in the language are not like C.
Instead, all expression elements are converted to the type of the destination before the operation, and integers are truncated.
Example:The expected output for this program is:
MLIR
Example 1
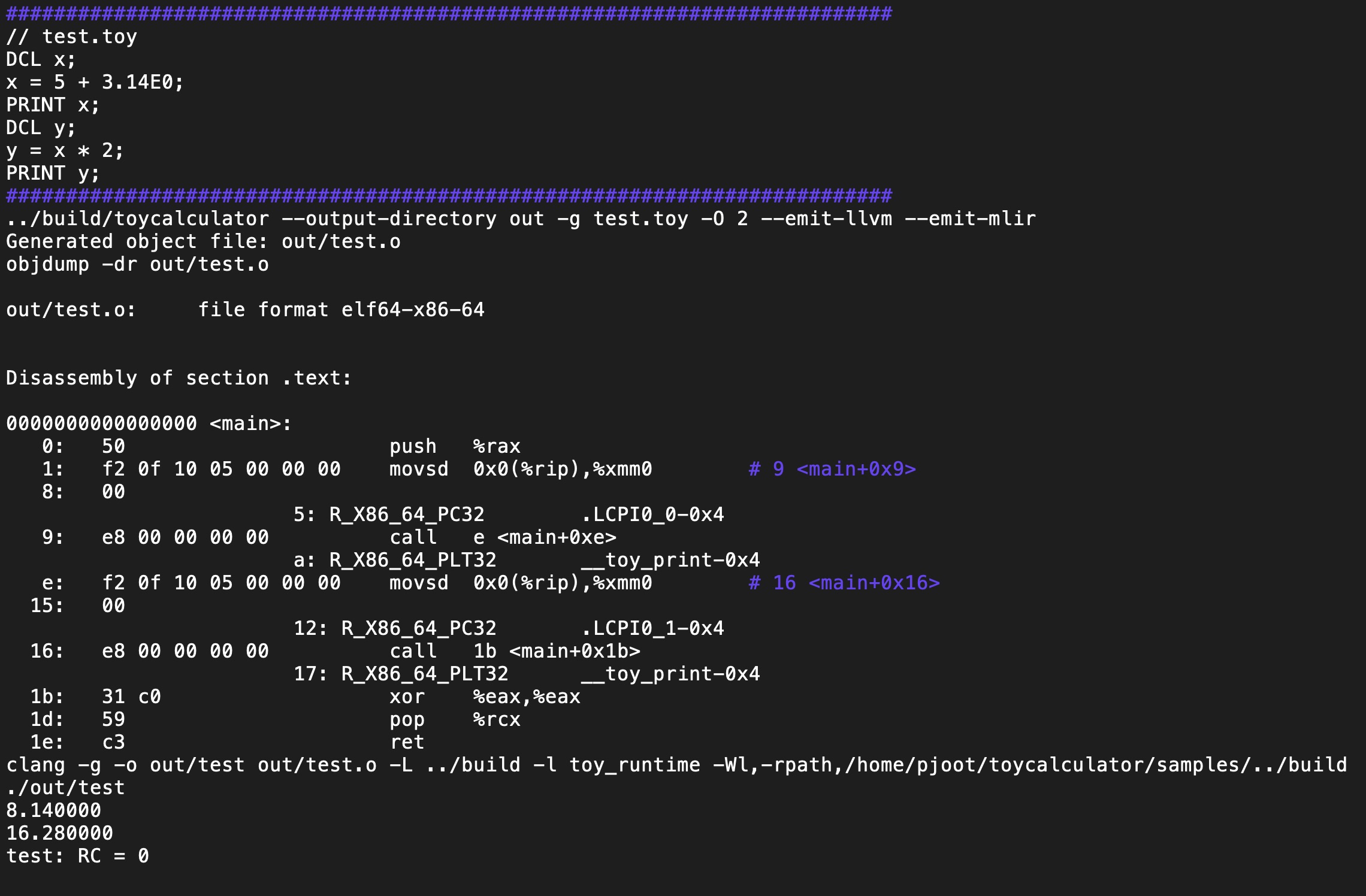
The MLIR for the language now matches the statements of the language much more closely. Consider test.toy for example:
for which the MLIR is now free of memref dialect:
"builtin.module"() ({
"toy.program"() ({
"toy.declare"() <{name = "x", type = f64}> : () -> () loc(#loc)
%0 = "arith.constant"() <{value = 5 : i64}> : () -> i64 loc(#loc1)
%1 = "arith.constant"() <{value = 3.140000e+00 : f64}> : () -> f64 loc(#loc1)
%2 = "toy.add"(%0, %1) : (i64, f64) -> f64 loc(#loc1)
"toy.assign"(%2) <{name = "x"}> : (f64) -> () loc(#loc1)
%3 = "toy.load"() <{name = "x"}> : () -> f64 loc(#loc2)
"toy.print"(%3) : (f64) -> () loc(#loc2)
"toy.declare"() <{name = "y", type = f64}> : () -> () loc(#loc3)
%4 = "toy.load"() <{name = "x"}> : () -> f64 loc(#loc4)
%5 = "arith.constant"() <{value = 2 : i64}> : () -> i64 loc(#loc4)
%6 = "toy.mul"(%4, %5) : (f64, i64) -> f64 loc(#loc4)
"toy.assign"(%6) <{name = "y"}> : (f64) -> () loc(#loc4)
%7 = "toy.load"() <{name = "y"}> : () -> f64 loc(#loc5)
"toy.print"(%7) : (f64) -> () loc(#loc5)
"toy.exit"() : () -> () loc(#loc)
}) : () -> () loc(#loc)
}) : () -> () loc(#loc)
#loc = loc("test.toy":1:1)
#loc1 = loc("test.toy":2:5)
#loc2 = loc("test.toy":3:1)
#loc3 = loc("test.toy":4:1)
#loc4 = loc("test.toy":5:5)
#loc5 = loc("test.toy":6:1)
Variable references still use llvm.alloca, but are symbol based in the builder, and llvm.alloca now doesn’t show up until lowering to LLVM-IR:
; ModuleID = 'test.toy'
source_filename = "test.toy"
declare void @__toy_print(double)
define i32 @main() {
%1 = alloca double, i64 1, align 8
store double 8.140000e+00, ptr %1, align 8
%2 = load double, ptr %1, align 8
call void @__toy_print(double %2)
%3 = alloca double, i64 1, align 8
%4 = load double, ptr %1, align 8
%5 = fmul double %4, 2.000000e+00
store double %5, ptr %3, align 8
%6 = load double, ptr %3, align 8
call void @__toy_print(double %6)
ret i32 0
}
!llvm.module.flags = !{!0}
!0 = !{i32 2, !"Debug Info Version", i32 3}
Here is an example generated assembly, for the program above:
0000000000000000 <main>: 0: push %rax 1: movsd 0x0(%rip),%xmm0 9: call e <main+0xe> e: movsd 0x0(%rip),%xmm0 16: call 1b <main+0x1b> 1b: xor %eax,%eax 1d: pop %rcx 1e: ret
Example 2
Here’s an example that highlights the new type support a bit better:
DESKTOP-16N83AG:/home/pjoot/toycalculator/samples> cat addi.toy INT32 x; x = 5 + 3.14E0; FLOAT64 f; f = x; PRINT f;
The MLIR for this is:
"builtin.module"() ({
"toy.program"() ({
"toy.declare"() <{name = "x", type = i32}> : () -> () loc(#loc)
%0 = "arith.constant"() <{value = 5 : i64}> : () -> i64 loc(#loc1)
%1 = "arith.constant"() <{value = 3.140000e+00 : f64}> : () -> f64 loc(#loc1)
%2 = "toy.add"(%0, %1) : (i64, f64) -> i32 loc(#loc1)
"toy.assign"(%2) <{name = "x"}> : (i32) -> () loc(#loc1)
"toy.declare"() <{name = "f", type = f64}> : () -> () loc(#loc2)
%3 = "toy.load"() <{name = "x"}> : () -> i32 loc(#loc3)
"toy.assign"(%3) <{name = "f"}> : (i32) -> () loc(#loc3)
%4 = "toy.load"() <{name = "f"}> : () -> f64 loc(#loc4)
"toy.print"(%4) : (f64) -> () loc(#loc4)
"toy.exit"() : () -> () loc(#loc)
}) : () -> () loc(#loc)
}) : () -> () loc(#loc)
#loc = loc("addi.toy":1:1)
#loc1 = loc("addi.toy":2:5)
#loc2 = loc("addi.toy":3:1)
#loc3 = loc("addi.toy":4:5)
#loc4 = loc("addi.toy":5:1)
for which the LLVM IR lowering result is:
; ModuleID = 'addi.toy'
source_filename = "addi.toy"
declare void @__toy_print(double)
define i32 @main() {
%1 = alloca i32, i64 1, align 4
store i32 8, ptr %1, align 4
%2 = alloca double, i64 1, align 8
%3 = load i32, ptr %1, align 4
%4 = sitofp i32 %3 to double
store double %4, ptr %2, align 8
%5 = load double, ptr %2, align 8
call void @__toy_print(double %5)
ret i32 0
}
!llvm.module.flags = !{!0}
!0 = !{i32 2, !"Debug Info Version", i32 3}
Because of lack of side effects, most of that code is obliterated in the assembly printing stage, leaving just: