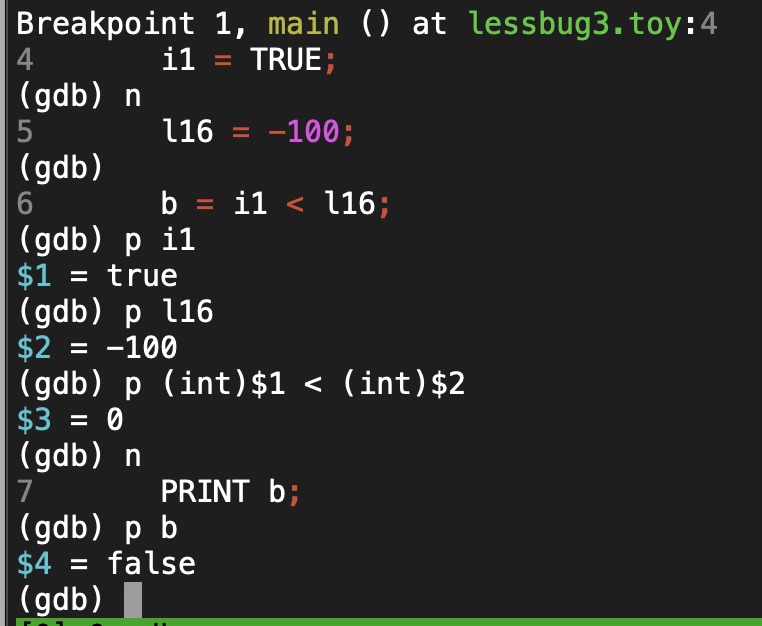
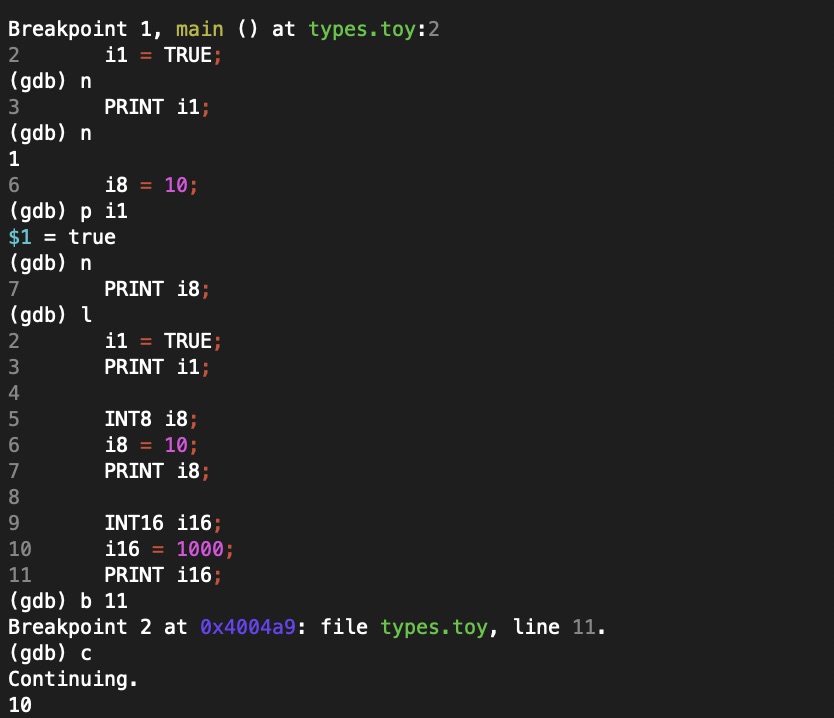
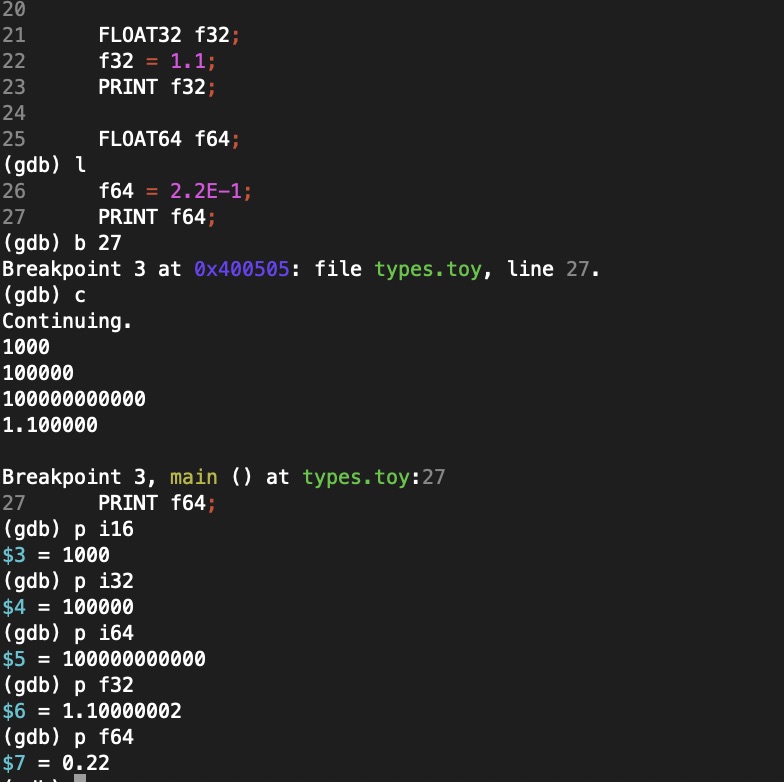
gdb session
I’ve added an alternate input source for the silly compiler. As well as the .silly files that it previously accepted, it now also accepts .mlir (silly-dialect) files as input.
This means that if there’s an experimental language feature that requires new style MLIR, but I don’t want to figure out how to push that all the way through grammar -> parser -> builder -> lowering all at once, I might be able to at least understand the required MLIR patterns by by manually modifying exiting MLIR (generated with ‘silly –emit-mlir’).
For example, I don’t have BREAK support for FOR loops. I can do something simple:
INT64 v;
FOR (INT64 myLoopVar : (1, 5))
{
PRINT myLoopVar;
v = myLoopVar + 1;
};
PRINT "after loop: ", v;
The MLIR for this (with location info stripped out), looks like:
fedoravm:/home/peeter/toycalculator/tests/endtoend/for> silly-opt --pretty -s out/for_simplest.mlir
module {
func.func @main() -> i32 {
%c0_i32 = arith.constant 0 : i32
%c5_i64 = arith.constant 5 : i64
%c1_i64 = arith.constant 1 : i64
"silly.scope"() ({
%0 = "silly.declare"() <{sym_name = "v"}> : () -> !silly.var
scf.for %arg0 = %c1_i64 to %c5_i64 step %c1_i64 : i64 {
"silly.print"(%c0_i32, %arg0) : (i32, i64) -> ()
%3 = "silly.add"(%arg0, %c1_i64) : (i64, i64) -> i64
silly.assign %0 : = %3 : i64
}
%1 = "silly.string_literal"() <{value = "after loop: "}> : () -> !llvm.ptr
%2 = silly.load %0 : : i64
"silly.print"(%c0_i32, %1, %2) : (i32, !llvm.ptr, i64) -> ()
"silly.return"(%c0_i32) : (i32) -> ()
}) : () -> ()
"silly.yield"() : () -> ()
}
}
If I want to add a BREAK into the mix (which I don’t support in any of grammar or parser or builder right now), something like:
INT64 v;
FOR (INT64 i : (1, 5)) {
PRINT i;
v = i + 1;
IF (i == 3) { BREAK; };
};
PRINT "after loop: ", v;
Then it can be done by replacing the scf.for with scf.while, and putting in additional termination condition logic. Example:
module {
func.func @main() -> i32 {
%c0_i32 = arith.constant 0 : i32
%c1_i64 = arith.constant 1 : i64
%c3_i64 = arith.constant 3 : i64
%c5_i64 = arith.constant 5 : i64
%true = arith.constant true
%false = arith.constant false
"silly.scope"() ({
%0 = "silly.declare"() <{sym_name = "v"}> : () -> !silly.var
scf.while (%i = %c1_i64, %broke = %false) : (i64, i1) -> (i64, i1) {
%not_broke = arith.xori %broke, %true : i1
%in_range = arith.cmpi slt, %i, %c5_i64 : i64
%continue = arith.andi %in_range, %not_broke : i1
scf.condition(%continue) %i, %broke : i64, i1
} do {
^bb0(%loop_var: i64, %break_flag: i1):
"silly.print"(%c0_i32, %loop_var) : (i32, i64) -> ()
%2 = "silly.add"(%loop_var, %c1_i64) : (i64, i64) -> i64
silly.assign %0 : = %2 : i64
%is_three = arith.cmpi eq, %loop_var, %c3_i64 : i64
%should_break = arith.ori %break_flag, %is_three : i1
%next = arith.addi %loop_var, %c1_i64 : i64
scf.yield %next, %should_break : i64, i1
}
%lit = "silly.string_literal"() <{value = "after loop: "}> : () -> !llvm.ptr
%p = silly.load %0 : : i64
"silly.print"(%c0_i32, %lit, %p) : (i32, !llvm.ptr, i64) -> ()
"silly.return"(%c0_i32) : (i32) -> ()
}) : () -> ()
"silly.yield"() : () -> ()
}
}
Now, here’s where things get cool. I noticed something curious when I looked at the .mlir dump from the MLIR parser (which I dumped to verify I was getting the expected round trip output before lowering). The MLIR parser, given only MLIR source, and no other location tagging, goes off and tags everything with location info for the MLIR source itself. Example:
#loc15 = loc("forbreak.mlsilly":27:12)
#loc16 = loc("forbreak.mlsilly":27:28)
module {
func.func @main() -> i32 {
%c0_i32 = arith.constant 0 : i32 loc(#loc2)
%c1_i64 = arith.constant 1 : i64 loc(#loc3)
%c3_i64 = arith.constant 3 : i64 loc(#loc4)
%c5_i64 = arith.constant 5 : i64 loc(#loc5)
%true = arith.constant true loc(#loc6)
%false = arith.constant false loc(#loc7)
"silly.scope"() ({
%0 = "silly.declare"() <{sym_name = "v"}> : () -> !silly.var loc(#loc9)
%1:2 = scf.while (%arg0 = %c1_i64, %arg1 = %false) : (i64, i1) -> (i64, i1) {
%4 = arith.xori %arg1, %true : i1 loc(#loc11)
%5 = arith.cmpi slt, %arg0, %c5_i64 : i64 loc(#loc12)
%6 = arith.andi %5, %4 : i1 loc(#loc13)
scf.condition(%6) %arg0, %arg1 : i64, i1 loc(#loc14)
} do {
^bb0(%arg0: i64 loc("forbreak.mlsilly":27:12), %arg1: i1 loc("forbreak.mlsilly":27:28)):
"silly.print"(%c0_i32, %arg0) : (i32, i64) -> () loc(#loc17)
%4 = "silly.add"(%arg0, %c1_i64) : (i64, i64) -> i64 loc(#loc18)
silly.assign %0 : = %4 : i64 loc(#loc19)
%5 = arith.cmpi eq, %arg0, %c3_i64 : i64 loc(#loc20)
%6 = arith.ori %arg1, %5 : i1 loc(#loc21)
%7 = arith.addi %arg0, %c1_i64 : i64 loc(#loc22)
scf.yield %7, %6 : i64, i1 loc(#loc23)
} loc(#loc10)
%2 = "silly.string_literal"() <{value = "after loop: "}> : () -> !llvm.ptr loc(#loc24)
%3 = silly.load %0 : : i64 loc(#loc25)
"silly.print"(%c0_i32, %2, %3) : (i32, !llvm.ptr, i64) -> () loc(#loc26)
"silly.return"(%c0_i32) : (i32) -> () loc(#loc27)
}) : () -> () loc(#loc8)
"silly.yield"() : () -> () loc(#loc28)
} loc(#loc1)
} loc(#loc)
#loc = loc("forbreak.mlsilly":9:1)
#loc1 = loc("forbreak.mlsilly":10:3)
#loc2 = loc("forbreak.mlsilly":11:15)
#loc3 = loc("forbreak.mlsilly":12:15)
#loc4 = loc("forbreak.mlsilly":13:15)
#loc5 = loc("forbreak.mlsilly":14:15)
#loc6 = loc("forbreak.mlsilly":15:13)
#loc7 = loc("forbreak.mlsilly":16:14)
...
My compiler can then turns that location info into dwarf DI, just as it does for regular .silly source file, so I can actually line step through the MLIR itself with any debugger! Here’s an example session:
Breakpoint 1, main () at forbreak.mlsilly:25
25 scf.condition(%continue) %i, %broke : i64, i1
(gdb) l
20
21 scf.while (%i = %c1_i64, %broke = %false) : (i64, i1) -> (i64, i1) {
22 %not_broke = arith.xori %broke, %true : i1
23 %in_range = arith.cmpi slt, %i, %c5_i64 : i64
24 %continue = arith.andi %in_range, %not_broke : i1
25 scf.condition(%continue) %i, %broke : i64, i1
26 } do {
27 ^bb0(%loop_var: i64, %break_flag: i1):
28 "silly.print"(%c0_i32, %loop_var) : (i32, i64) -> ()
29 %2 = "silly.add"(%loop_var, %c1_i64) : (i64, i64) -> i64
(gdb) l
30 silly.assign %0 : = %2 : i64
31
32 %is_three = arith.cmpi eq, %loop_var, %c3_i64 : i64
33 %should_break = arith.ori %break_flag, %is_three : i1
34
35 %next = arith.addi %loop_var, %c1_i64 : i64
36 scf.yield %next, %should_break : i64, i1
37 }
38
39 %lit = "silly.string_literal"() <{value = "after loop: "}> : () -> !llvm.ptr
(gdb) b 32
Breakpoint 2 at 0x40076c: file forbreak.mlsilly, line 32.
(gdb) c
Continuing.
1
Breakpoint 2, main () at forbreak.mlsilly:32
32 %is_three = arith.cmpi eq, %loop_var, %c3_i64 : i64
(gdb) disassemble
Dump of assembler code for function main:
0x000000000040072c <+0>: sub sp, sp, #0x60
0x0000000000400730 <+4>: stp x30, x21, [sp, #64]
0x0000000000400734 <+8>: stp x20, x19, [sp, #80]
0x0000000000400738 <+12>: mov w19, wzr
0x000000000040073c <+16>: mov w20, #0x1 // #1
0x0000000000400740 <+20>: mov w21, #0x1 // #1
0x0000000000400744 <+24>: str xzr, [sp, #8]
0x0000000000400748 <+28>: cmp x21, #0x4
0x000000000040074c <+32>: b.gt 0x400784
0x0000000000400750 <+36>: tbnz w19, #0, 0x400784
0x0000000000400754 <+40>: add x1, sp, #0x10
0x0000000000400758 <+44>: mov w0, #0x1 // #1
0x000000000040075c <+48>: stp x21, xzr, [sp, #24]
0x0000000000400760 <+52>: str x20, [sp, #16]
0x0000000000400764 <+56>: bl 0x4005b0 <__silly_print@plt>
0x0000000000400768 <+60>: add x21, x21, #0x1
=> 0x000000000040076c <+64>: cmp x21, #0x4
0x0000000000400770 <+68>: str x21, [sp, #8]
0x0000000000400774 <+72>: cset w8, eq // eq = none
0x0000000000400778 <+76>: orr w19, w19, w8
0x000000000040077c <+80>: cmp x21, #0x4
0x0000000000400780 <+84>: b.le 0x400750
0x0000000000400784 <+88>: mov x8, #0x3 // #3
0x0000000000400788 <+92>: ldr x9, [sp, #8]
0x000000000040078c <+96>: mov w10, #0xc // #12
0x0000000000400790 <+100>: movk x8, #0x1, lsl #32
0x0000000000400794 <+104>: add x1, sp, #0x10
0x0000000000400798 <+108>: mov w0, #0x2 // #2
0x000000000040079c <+112>: stp x8, x10, [sp, #16]
0x00000000004007a0 <+116>: adrp x8, 0x400000
0x00000000004007a4 <+120>: add x8, x8, #0x7f8
0x00000000004007a8 <+124>: stp x9, xzr, [sp, #48]
0x00000000004007ac <+128>: mov w9, #0x1 // #1
0x00000000004007b0 <+132>: stp x8, x9, [sp, #32]
0x00000000004007b4 <+136>: bl 0x4005b0 <__silly_print@plt>
0x00000000004007b8 <+140>: ldp x20, x19, [sp, #80]
0x00000000004007bc <+144>: mov w0, wzr
0x00000000004007c0 <+148>: ldp x30, x21, [sp, #64]
0x00000000004007c4 <+152>: add sp, sp, #0x60
0x00000000004007c8 <+156>: ret
End of assembler dump.
(gdb) c
Continuing.
2
Breakpoint 2, main () at forbreak.mlsilly:32
32 %is_three = arith.cmpi eq, %loop_var, %c3_i64 : i64
(gdb) p v
$2 = 2
Having built a compiler for an arbitrary language, and having implemented DWARF instrumentation for that language, I get line support for stepping through the MLIR itself, if I want it.
I can imagine a scenerio where I’ve screwed up the MLIR ops generation in the builder. This lets me set a breakpoint right at the MLIR line in question, and poke around at the disassembly for that point in the code, and see what’s going on. What a cool compiler debugging tool!