Here’s more notes from reading Stroustrup’s “The C++ Programming Language, 4th edition”
throw() as noexcept equivalent
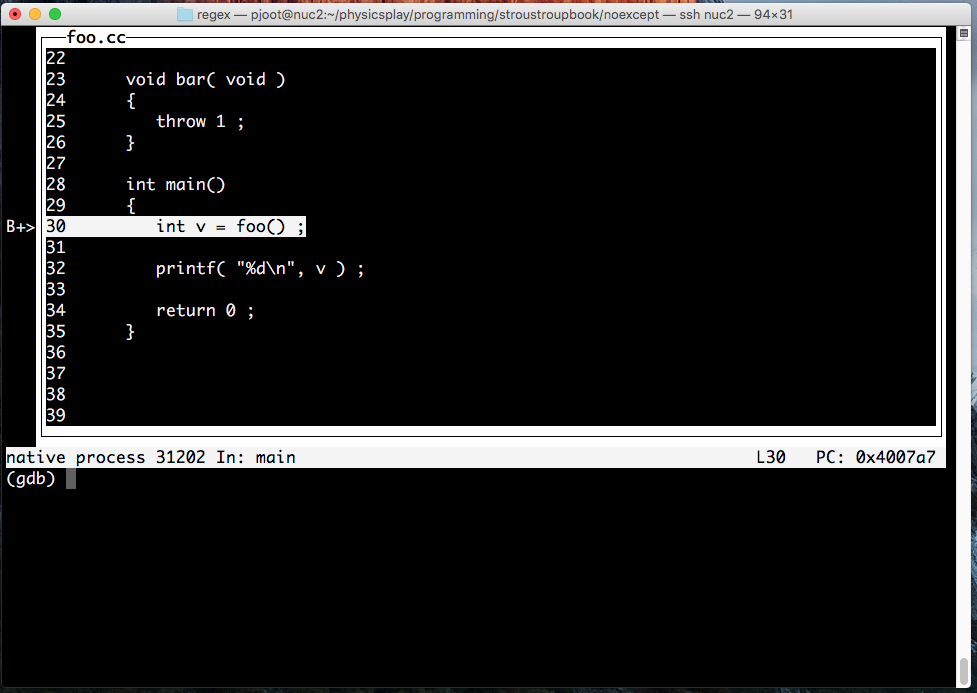
throw() without any exception types can be used as an equivalent to the new noexcept keyword. Stroustrup also mentions that explicit throw() clauses
haven’t worked out well in practise, and is deprecated.
try scopes as function body
It turns out that try clauses can be used as function bodies, as in
This can also be done for constructor and destructor bodies as in
so that a throw in the class field member construction can also be caught.
Inline (default) namespace
There is a mechanism for namespace versioning. Suppose that you want a new V2 namespace to be the default, you can do:
namespace myproject
{
inline namespace V2
{
struct X {
int x ;
int y ;
} ;
void foo( const X & ) ;
}
namespace V1
{
struct X {
int x ;
} ;
void foo( const X & ) ;
}
}
Existing callers of the library that are using V1 interfaces can continue to work unmodified, but new callers will use the V2::X and V2::foo interfaces, and the library can provide both interfaces, one for compatibility and another for new code:
void myproject::V2::foo( const myproject::V2::X & )
{
// ...
}
void myproject::V1::foo( const myproject::V1::X & )
{
// ...
}
Unnamed namespaces.
I’d once seen unnamed namespaces as a modern C++ (more general) replacement for static functions. To see if such namespace functions are optimized away in the same fashion as a static function, I tried
#include <stdio.h>
namespace
{
void foo()
{
printf( "ns:foo\n" ) ;
}
}
int main()
{
foo() ;
return 0 ;
}
This example uses printf and not std::cout because I wanted to look at the assembly listing and cout’s listing, at least on a mac, was completely abysmal. foo() was optimized away, but that’s a lot easier to see in the C printf listing:
$ make c++ -o n -std=c++11 -O2 n.cc $ otool -tV n | less n: (__TEXT,__text) section _main: 0000000100000f70 pushq %rbp 0000000100000f71 movq %rsp, %rbp 0000000100000f74 leaq 0x2b(%rip), %rdi ## literal pool for: "ns:foo" 0000000100000f7b callq 0x100000f84 ## symbol stub for: _puts 0000000100000f80 xorl %eax, %eax 0000000100000f82 popq %rbp 0000000100000f83 retq
at_quick_exit
There’s now also a mechanism to exit and avoid global destructors and atexit routines from being evaluated. Here’s an example
#include <cstdlib>
#include <iostream>
extern "C"
void normalexit()
{
std::cout << "normalexit\n" ;
}
extern "C"
void quickCexit()
{
std::cout << "quickCexit\n" ;
}
void quickCPPexit()
{
std::cout << "quickCPPexit\n" ;
}
class X
{
public:
~X()
{
std::cout << "X::~X()\n" ;
}
} x ;
int main( int argc, char ** argv )
{
atexit( normalexit ) ;
std::at_quick_exit( quickCexit ) ;
std::at_quick_exit( quickCPPexit ) ;
if ( argc == 1 )
{
std::quick_exit( 3 ) ;
}
when run without arguments (argc == 1), we get
[sourcecode language="bash"]
$ ./at
quickCPPexit
quickCexit
whereas if the normal exit processing is allowed to complete we see global destructors and regular atexit calls
Observe, unlike atexit, which can only (portably) take extern “C” defined functions, at_quick_exit can take functions with both C and C++ linkage.
Enum default
It was not obvious to me what the default value for an enum class (or enum) should be (the first value, an invalid value, zero, …)? It turns out that the default is zero, as printed by the following fragment
#include <iostream>
enum class x { v = 1, w } ;
enum y { vv = 1, ww } ;
int main()
{
x e1 = {} ;
y e2 = {} ;
std::cout << (int)e1 << '\n' ;
std::cout << e2 << '\n' ;
return 0 ;
}
Note that an explicit cast is required for enum class values, but not for enum, which are by default, int convertible.
default initialization with new
The uniform initializer syntax can also be used with new calls. Here’s an example with uninitialized and default initialized double allocations
#include <stdio.h>
int main()
{
double * d1 = new double ;
double * d2 = new double{} ;
printf( "%g %g\n", *d1, *d2 ) ;
return 0 ;
}
Observe that we get nice garbage values for *d1, but *d2 is always 0.0:
initializer_list
I remember really wanting a feature like this eons ago when I first wrote a matrix template class in 1st year. Here’s a sample of how it could be used
#include <iostream>
#include <vector>
#include <string>
template <unsigned r, unsigned c>
class m
{
std::vector<double> mat ;
public:
class bad_init {} ;
m() : mat(r*c) {}
m( std::initializer_list<double> i ) : mat( r * c )
{
if ( i.size() > ( r * c ) )
{
throw bad_init() ;
}
int p{} ;
for ( auto v : i )
{
mat[ p++ ] = v ;
}
}
void dump( const std::string & n ) const
{
const char * sep = ": " ;
std::cout << n ;
for ( auto v : mat )
{
std::cout << sep << v ;
sep = ", " ;
}
std::cout << '\n' ;
}
} ;
int main()
{
m< 3, 2 > v1 ;
m< 3, 2 > v2{ 0., 1., 2., 3., 4. } ;
v1.dump( "v1" ) ;
v2.dump( "v2" ) ;
m< 3, 2 > v3{ 0., 1., 2., 3., 4., 5., 6., 7. } ;
return 0 ;
}
This produces the two dumps and the expected std::terminate call for the wrong (too many) parameters on the third construction attempt