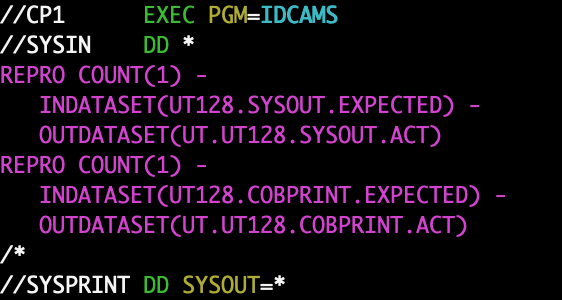
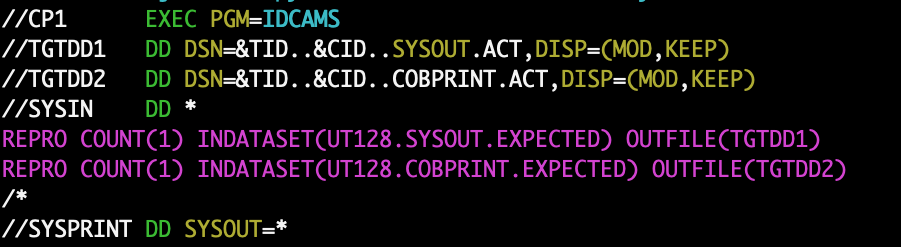
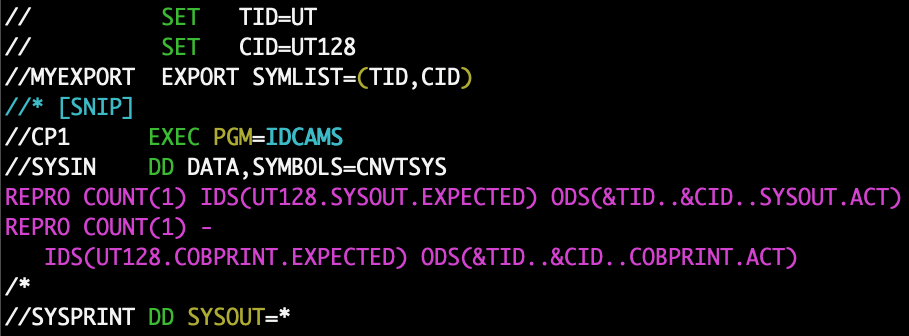
I encountered customer COBOL code today with a file declaration of the following form:
000038 SELECT AUSGABE ASSIGN TO UR-S-AUSGABE 000039 ACCESS IS SEQUENTIAL. ... 000056 FD AUSGABE 000057 RECORDING F 000058 BLOCK 0 RECORDS 000059 LABEL RECORDS OMITTED.
where the program’s JCL used an AUSGABE (German “output”) DDNAME of the following form:
The SELECT looked completely wrong to me, as I thought that SELECT is supposed to have the form:
That’s the syntax that my Murach’s Mainframe COBOL uses, and also what I’d seen in big-blue’s documentation.
However, in this customer’s code, the identifier UR-S-AUSGABE is longer than 8 characters, so it sure didn’t look like a DDNAME. I preprocessed the code looking to see if UR-S-AUSGABE was hiding in a copybook (mainframe lingo for an include file), but it wasn’t. How on Earth did this work when it was compiled and run on the original mainframe?
It turns out that [LABEL-]S- or [LABEL]-AS- are ways that really old COBOL code used to specify file organization (something like PL/I’s ENV(ORGANIZATION) clauses for FILEs). This works on the mainframe because a “modern” mainframe COBOL compiler strips off the LABEL- prefix if specified and the organization prefix S- as well, essentially treating those identifier fragments as “comments”.
For anybody reading this who has only programmed in a sane programming language, on sane operating systems, this all probably sounds like verbal diarrhea. What on earth is a file organization and ddname? Do I really have to care about those just to access a file? Well, on the mainframe, yes, you do.
These mysterious dependencies highlight a number of reasons why COBOL code is hard to migrate. It isn’t just a programming language, but it is tied to the mainframe with lots of historic baggage in ways that are very difficult to extricate. Even just to understand how to open a file in mainframe COBOL you have a whole pile of obstacles along the learning curve:
- You don’t just run the program in a shell, passing in arguments, but you have to construct a JCL job step to do so. This specifies parameters, environment variables, file handles, and other junk.
- You have to know what a DDNAME is. This is like a HANDLE in the JCL code that refers to a file. The file has a filename (DSNAME), but you don’t typically use that. Instead the JCL’s job step declares an arbitrary DDNAME to refer to that handle, and the program that is run in that job step has to always refer to the file using that abstract handle.
- The file has all sorts of esoteric attributes that you have to know about to access it properly (fixed, variable, blocked, record length, block size, …). The program that accesses the file typically has to make sure that these attributes are all encoded with the equivalent language specific syntax.
- Files are not typically just byte streams on the mainframe but can have internal structure that can be as complicated as a simple database (keyed records, with special modes to access them to initialize vs access/modify.)
- To make life extra “fun”, files are found in a variety of EBCDIC code pages. In some cases these can’t be converted to single byte iso-8859-X code pages, so you have to use utf-8, and can get into trouble if you want to do round trip conversions.
- Because of the internal structure of a mainframe file, you may not be able to transfer it to a sane operating system unless special steps are taken. For example, a variable format file with binary data would typically have to be converted to a fixed format representation so that it’s possible to seek from record to record.
- Within the (COBOL) code you have three sets of attributes that you have to specify to “declare” a file, before you can even attempt to open it: the DDNAME to COBOL-file-name mapping (SELECT), the FD clause (file properties), and finally record declarations (global variables that mirror the file data record structure that you have to use to read and write the file.)
You can’t just learn to program COBOL, like you would any sane programming language, but also have to learn all the mainframe concepts that the COBOL code is dependent on. Make sure you are close enough to your eyewash station before you start!