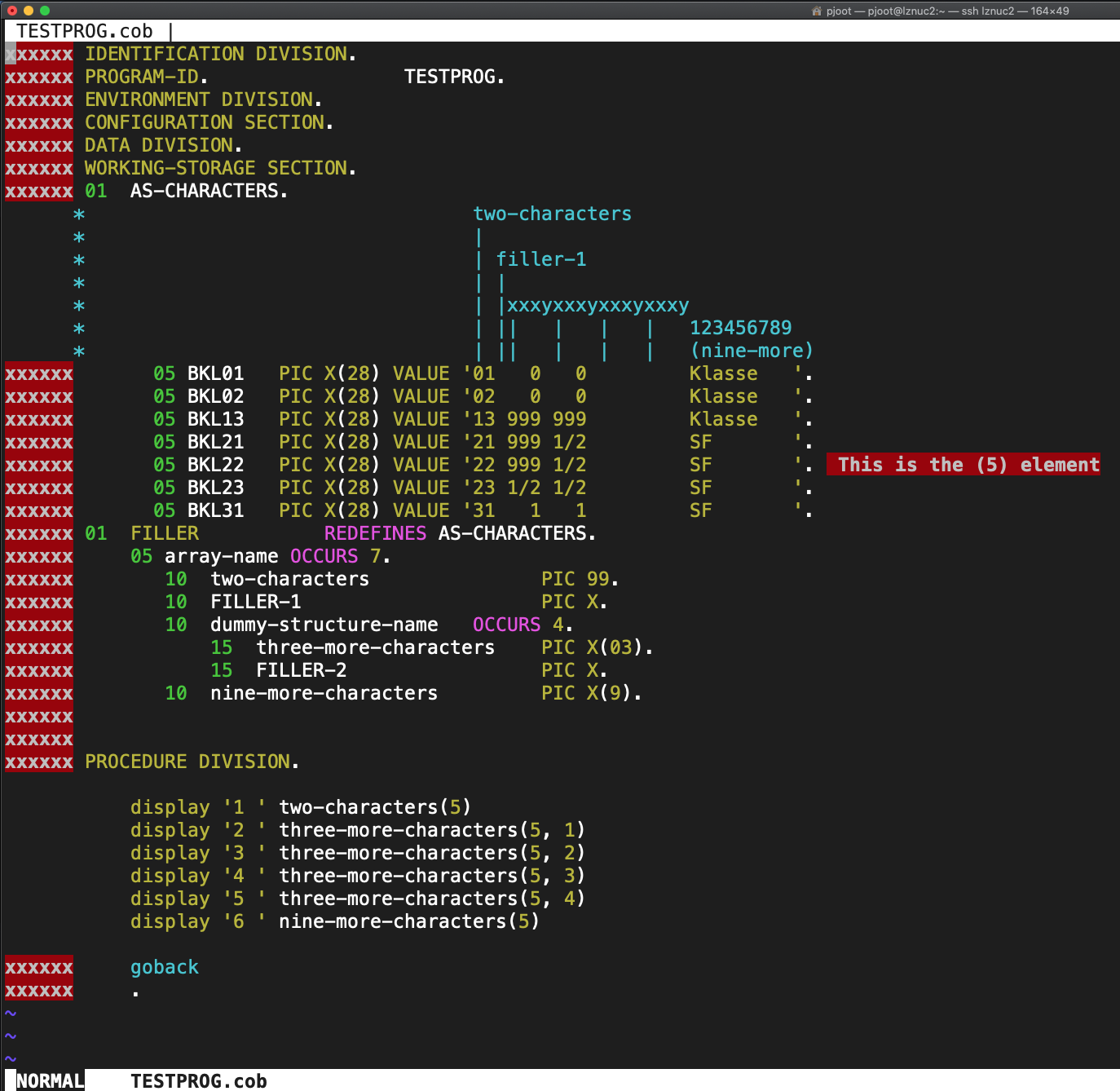
Another day, another surprise from COBOL. I was debugging a failure in a set of COBOL programs, and it seemed that the place things started going wrong was a specific IF check, which basically looked like:

The original code was triple incomprehensible, as it:
- Was in German.
- Was in COBOL.
- Was generated by DELTA and was completely disgusting spaghetti code. A map of the basic blocks would have looked like it was colored by a three year old vigorously scribbling with a crayon.
It turns out that there was a whole pile of error handling code that happened after the IF check, and I correctly guessed that there was something wrong with how our compiler handled the IF statement.
What I didn’t guess was what the actual operator precedence in this IF check was. Initially, my C programmer trained mind looked at that IF condition, and said “what the hell is that!?” I then guessed, incorrectly, that it meant:
if ( X != SPACES and X = ZERO)
where X is the array slice expression. That interpretation did not explain the runtime failure, so I was hoping that I was both wrong about what it meant, but right that there was a compiler bug.
It turns out that in COBOL the implicit operator for the second part of the IF statement is ‘NOT =’. i.e. the NOT= distributes over the AND, so this IF actually meant:
if ( X != SPACES and X != ZERO)
In the original program, that IF condition actually makes sense. After some reflection, I see there is some sense to this distribution, but it certainly wasn’t intuitive after programming C and C++ for 27 years. I’d argue that the root cause of the confusion is COBOL itself. A real programming language would use a temporary variable for the really long array slice expression, which would obliterate the need for counter-intuitive operator distribution requirements. Imagine something like:
VAR X = PAYLOAD-DATA(PAYLOAD-START(TALLY): PAYLOAD-END(TALLY))
IF (X NOT = SPACES) AND (X NOT = LOW-VALUE)
NEXT SENTENCE ELSE GO TO CHECK-IT-DONE.
(Incidentally LOW-VALUE means binary-zero, not a ‘0’ character that has a 0xF0 value in EBCDIC).
COBOL is made especially incomprehensible since you can’t declare an in-line temporary in COBOL. If you want one, you have to go thousands of lines up in the code to the WORKING-STORAGE section, and put a variable in there somewhere. Such a variable is global to the whole program, and you have to search to determine it’s usage scope. You probably also need a really long name for it because of namespace collision with all the other global variables. Basically, you are better off not using any helper variables, unless you want to pay an explicit cost in overall code complexity.
In my test program that illustrated the compiler bug, I made other COBOL errors. I blame the fact that I was using gross GOTO ridden code like the original. Here was my program:
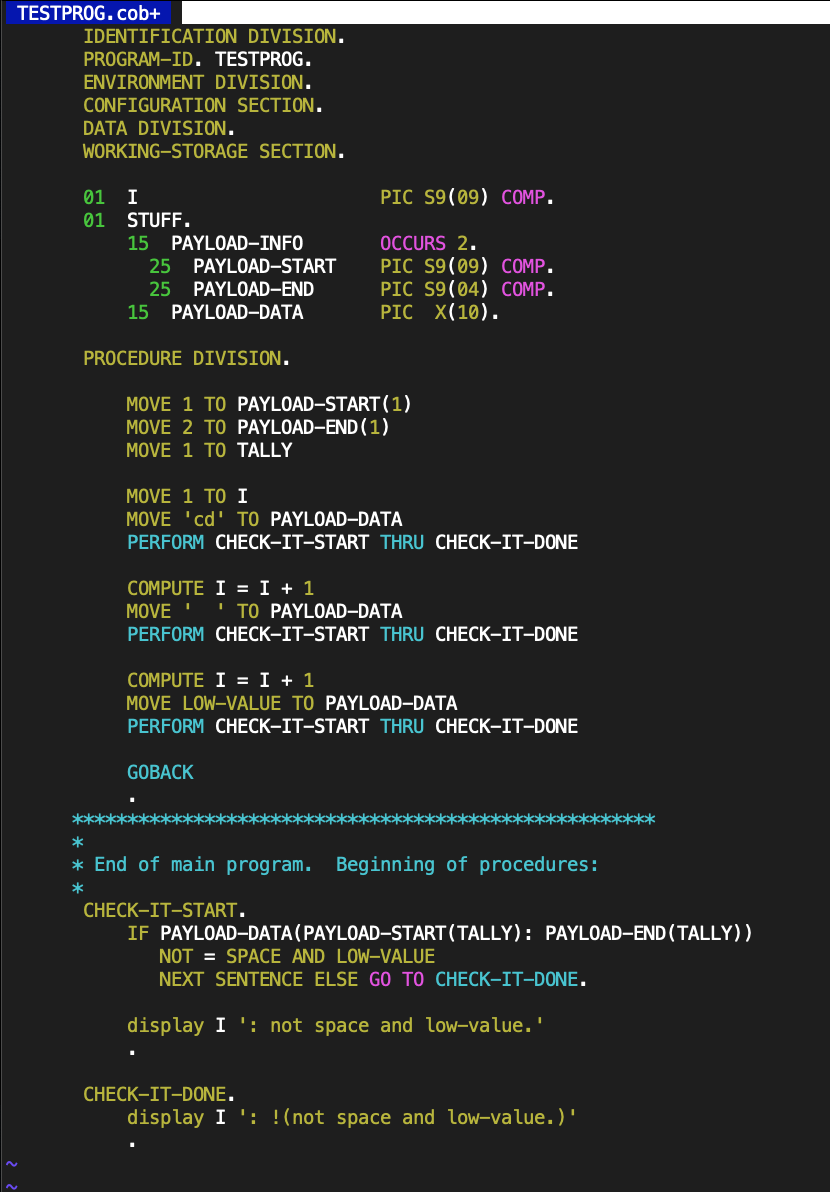
Because I misinterpreted the NOT= distribution, I thought this should produce:
000000001: !(not space and low-value.) 000000002: !(not space and low-value.) 000000003: !(not space and low-value.) 000000003: not space and low-value.
Once the subtle compiler bug was fixed, the actual SYSOUT from the program was:
000000001: not space and low-value. 000000001: !(not space and low-value.) 000000002: !(not space and low-value.) 000000003: !(not space and low-value.)
See how both the TRUE and FALSE basic blocks executed in my code. That didn’t occur in the original code, because it used an additional dummy EXIT paragraph to end the PERFORM range, and had a GOTO out of the first paragraph.
There is more modern COBOL syntax that can avoid this GOTO hell, but I hadn’t used it, as I kept the reproducer somewhat like the original code.