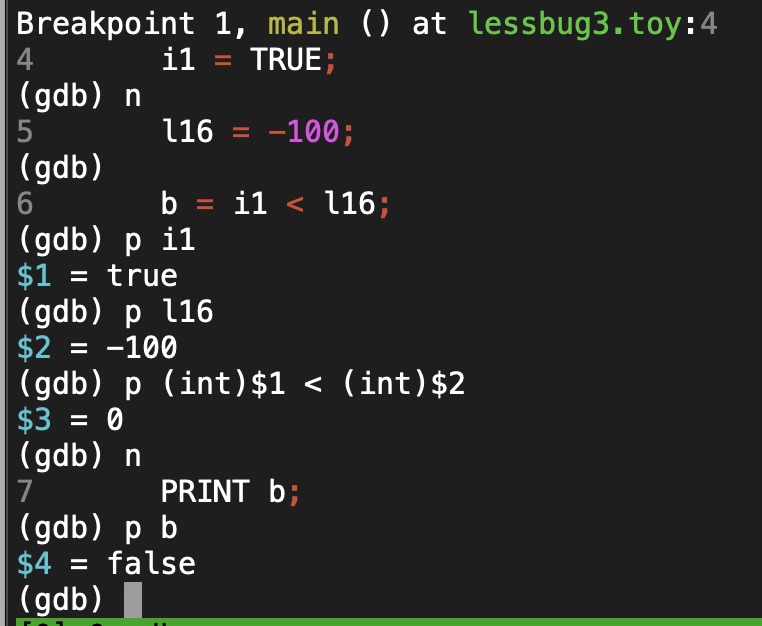
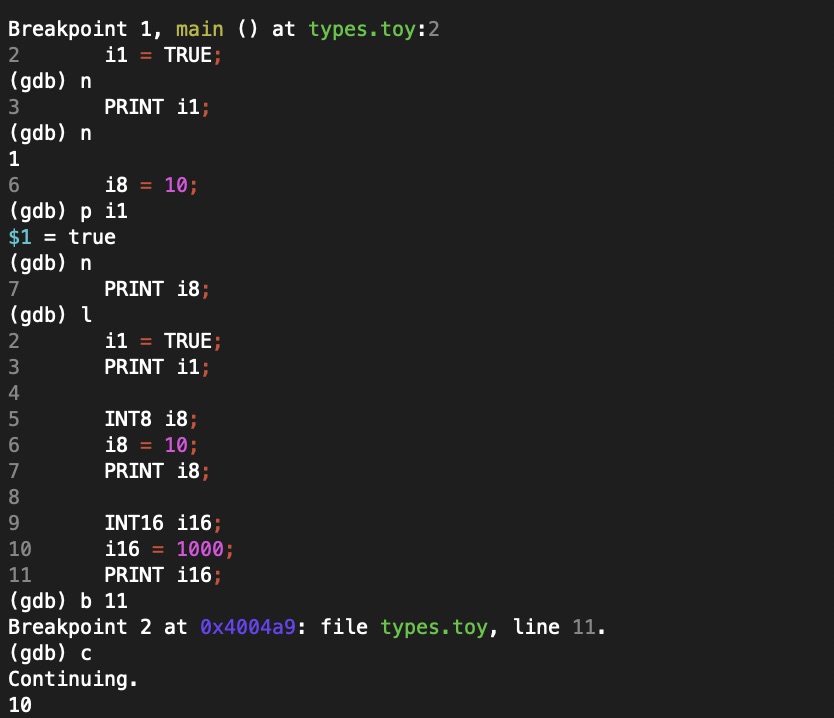
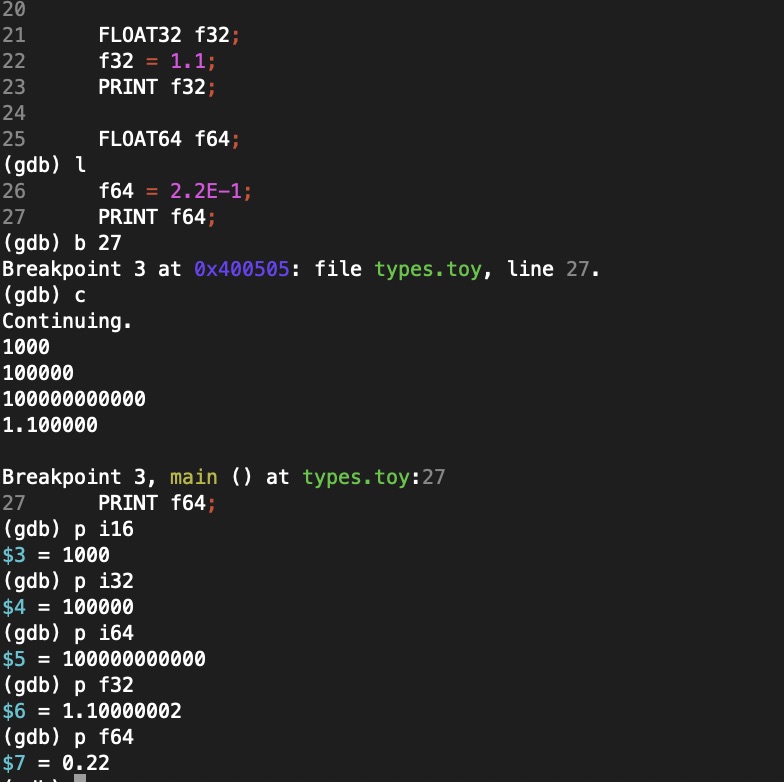
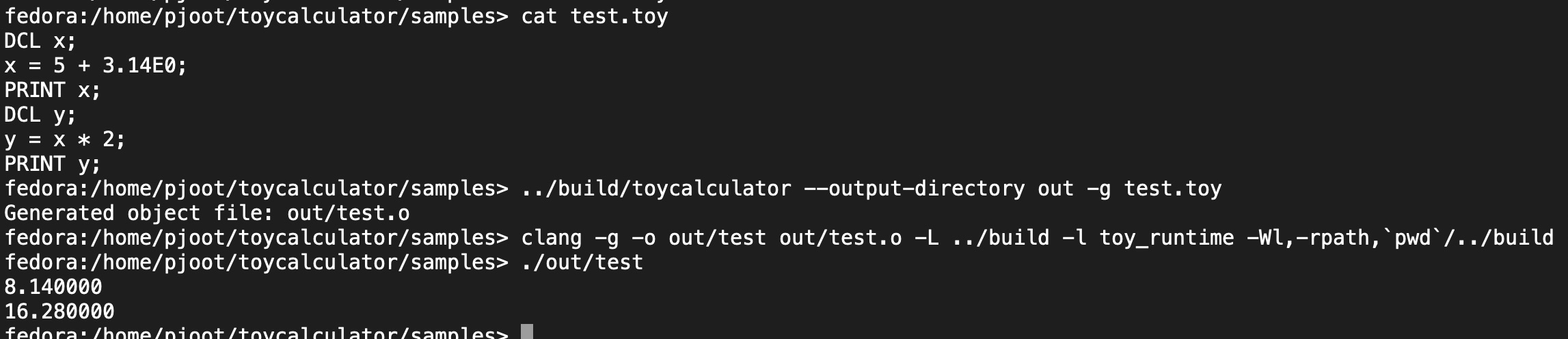
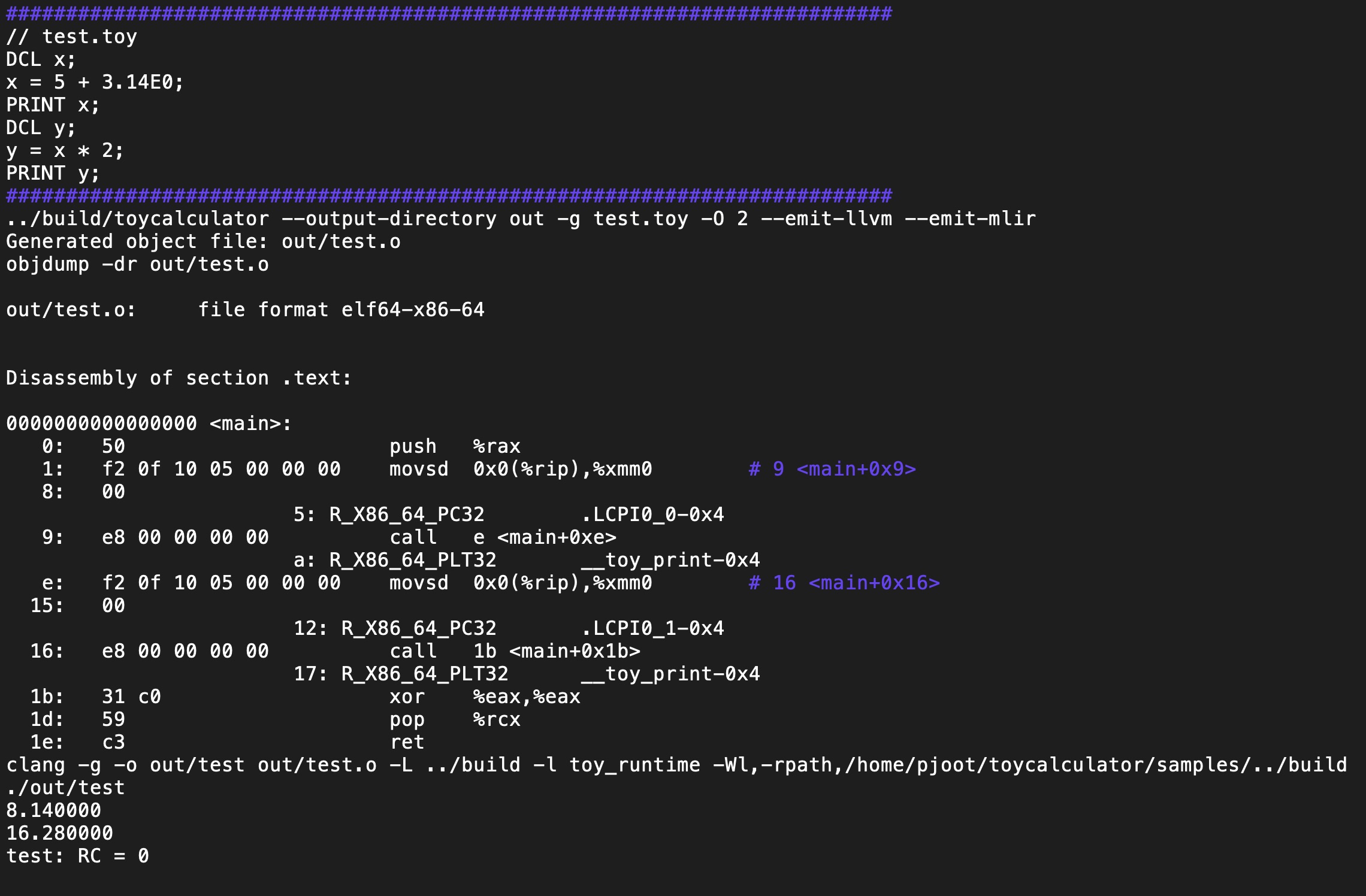
I’ve gotten my toy compiler project to the stage where I can generate a program, compile and run it. Here’s a little example:

Screenshot
This is the MLIR that is generated for this little program:
"builtin.module"() ({
"toy.program"() ({
"toy.declare"() <{name = "x", type = f64}> : () -> () loc(#loc)
%0 = "arith.constant"() <{value = 5 : i64}> : () -> i64 loc(#loc1)
%1 = "arith.constant"() <{value = 3.140000e+00 : f64}> : () -> f64 loc(#loc1)
%2 = "toy.add"(%0, %1) : (i64, f64) -> f64 loc(#loc1)
"toy.assign"(%2) <{name = "x"}> : (f64) -> () loc(#loc1)
%3 = "toy.load"() <{name = "x"}> : () -> f64 loc(#loc2)
"toy.print"(%3) : (f64) -> () loc(#loc2)
"toy.declare"() <{name = "y", type = f64}> : () -> () loc(#loc3)
%4 = "toy.load"() <{name = "x"}> : () -> f64 loc(#loc4)
%5 = "arith.constant"() <{value = 2 : i64}> : () -> i64 loc(#loc4)
%6 = "toy.mul"(%4, %5) : (f64, i64) -> f64 loc(#loc4)
"toy.assign"(%6) <{name = "y"}> : (f64) -> () loc(#loc4)
%7 = "toy.load"() <{name = "y"}> : () -> f64 loc(#loc5)
"toy.print"(%7) : (f64) -> () loc(#loc5)
"toy.exit"() : () -> () loc(#loc)
}) : () -> () loc(#loc)
}) : () -> () loc(#loc)
#loc = loc("test.toy":1:1)
#loc1 = loc("test.toy":2:5)
#loc2 = loc("test.toy":3:1)
#loc3 = loc("test.toy":4:1)
#loc4 = loc("test.toy":5:5)
#loc5 = loc("test.toy":6:1)
Notice how the location information is baked into the cake. After lowering of all the MLIR operations to LLVM-IR (except for the top most MLIR module), we have:
"builtin.module"() ({
"llvm.func"() <{CConv = #llvm.cconv, function_type = !llvm.func, linkage = #llvm.linkage, sym_name = "__toy_print_f64", visibility_ = 0 : i64}> ({
}) : () -> () loc(#loc)
"llvm.func"() <{CConv = #llvm.cconv, function_type = !llvm.func, linkage = #llvm.linkage, sym_name = "__toy_print_i64", visibility_ = 0 : i64}> ({
}) : () -> () loc(#loc)
"llvm.func"() <{CConv = #llvm.cconv, function_type = !llvm.func, linkage = #llvm.linkage, sym_name = "main", visibility_ = 0 : i64}> ({
%0 = "llvm.mlir.constant"() <{value = 1 : i64}> : () -> i64 loc(#loc)
%1 = "llvm.alloca"(%0) <{alignment = 8 : i64, elem_type = f64}> : (i64) -> !llvm.ptr loc(#loc)
%2 = "llvm.mlir.constant"() <{value = 5 : i64}> : () -> i64 loc(#loc1)
%3 = "llvm.mlir.constant"() <{value = 3.140000e+00 : f64}> : () -> f64 loc(#loc1)
%4 = "llvm.sitofp"(%2) : (i64) -> f64 loc(#loc1)
%5 = "llvm.fadd"(%4, %3) <{fastmathFlags = #llvm.fastmath}> : (f64, f64) -> f64 loc(#loc1)
"llvm.store"(%5, %1) <{ordering = 0 : i64}> : (f64, !llvm.ptr) -> () loc(#loc1)
%6 = "llvm.load"(%1) <{ordering = 0 : i64}> : (!llvm.ptr) -> f64 loc(#loc2)
"llvm.call"(%6) <{CConv = #llvm.cconv, TailCallKind = #llvm.tailcallkind, callee = @__toy_print_f64, fastmathFlags = #llvm.fastmath, op_bundle_sizes = array, operandSegmentSizes = array}> : (f64) -> () loc(#loc2)
%7 = "llvm.alloca"(%0) <{alignment = 8 : i64, elem_type = f64}> : (i64) -> !llvm.ptr loc(#loc3)
%8 = "llvm.load"(%1) <{ordering = 0 : i64}> : (!llvm.ptr) -> f64 loc(#loc4)
%9 = "llvm.mlir.constant"() <{value = 2 : i64}> : () -> i64 loc(#loc4)
%10 = "llvm.sitofp"(%9) : (i64) -> f64 loc(#loc4)
%11 = "llvm.fmul"(%8, %10) <{fastmathFlags = #llvm.fastmath}> : (f64, f64) -> f64 loc(#loc4)
"llvm.store"(%11, %7) <{ordering = 0 : i64}> : (f64, !llvm.ptr) -> () loc(#loc4)
%12 = "llvm.load"(%7) <{ordering = 0 : i64}> : (!llvm.ptr) -> f64 loc(#loc5)
"llvm.call"(%12) <{CConv = #llvm.cconv, TailCallKind = #llvm.tailcallkind, callee = @__toy_print_f64, fastmathFlags = #llvm.fastmath, op_bundle_sizes = array, operandSegmentSizes = array}> : (f64) -> () loc(#loc5)
%13 = "llvm.mlir.constant"() <{value = 0 : i32}> : () -> i32 loc(#loc)
"llvm.return"(%13) : (i32) -> () loc(#loc)
}) : () -> () loc(#loc)
}) : () -> () loc(#loc)
#loc = loc("../samples/test.toy":1:1)
#loc1 = loc("../samples/test.toy":2:5)
#loc2 = loc("../samples/test.toy":3:1)
#loc3 = loc("../samples/test.toy":4:1)
#loc4 = loc("../samples/test.toy":5:5)
#loc5 = loc("../samples/test.toy":6:1)
All is still good. See how all the location information has been retained through the lowering to LLVM-IR transformations. However, as soon as we run mlir::translateModuleToLLVMIR, our final LLVM-IR ends up stripped of all the location information:
; ModuleID = '../samples/test.toy'
source_filename = "../samples/test.toy"
declare void @__toy_print_f64(double)
declare void @__toy_print_i64(i64)
define i32 @main() {
%1 = alloca double, i64 1, align 8
store double 8.140000e+00, ptr %1, align 8
%2 = load double, ptr %1, align 8
call void @__toy_print_f64(double %2)
%3 = alloca double, i64 1, align 8
%4 = load double, ptr %1, align 8
%5 = fmul double %4, 2.000000e+00
store double %5, ptr %3, align 8
%6 = load double, ptr %3, align 8
call void @__toy_print_f64(double %6)
ret i32 0
}
!llvm.module.flags = !{!0}
!0 = !{i32 2, !"Debug Info Version", i32 3}
If we build a simple standalone C program with clang, it’s a much different story:
int main() {
int x = 42;
return 0;
}
fedora:/home/pjoot/toycalculator/prototypes> clang -g -S -emit-llvm test.c
fedora:/home/pjoot/toycalculator/prototypes> cat test.s
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-redhat-linux-gnu"
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 !dbg !8 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 0, ptr %1, align 4
#dbg_declare(ptr %2, !13, !DIExpression(), !14)
store i32 42, ptr %2, align 4, !dbg !14
ret i32 0, !dbg !15
}
attributes #0 = { noinline nounwind optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cmov,+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.dbg.cu = !{!0}
!llvm.module.flags = !{!2, !3, !4, !5, !6}
!llvm.ident = !{!7}
!0 = distinct !DICompileUnit(language: DW_LANG_C11, file: !1, producer: "clang version 20.1.3 (Fedora 20.1.3-1.fc42)", isOptimized: false, runtimeVersion: 0, emissionKind: FullDebug, splitDebugInlining: false, nameTableKind: None)
!1 = !DIFile(filename: "test.c", directory: "/home/pjoot/toycalculator/prototypes", checksumkind: CSK_MD5, checksum: "8d269ab8efc2854a823fb05a50ccf4b0")
!2 = !{i32 7, !"Dwarf Version", i32 5}
!3 = !{i32 2, !"Debug Info Version", i32 3}
!4 = !{i32 1, !"wchar_size", i32 4}
!5 = !{i32 7, !"uwtable", i32 2}
!6 = !{i32 7, !"frame-pointer", i32 2}
!7 = !{!"clang version 20.1.3 (Fedora 20.1.3-1.fc42)"}
!8 = distinct !DISubprogram(name: "main", scope: !1, file: !1, line: 1, type: !9, scopeLine: 1, spFlags: DISPFlagDefinition, unit: !0, retainedNodes: !12)
!9 = !DISubroutineType(types: !10)
!10 = !{!11}
!11 = !DIBasicType(name: "int", size: 32, encoding: DW_ATE_signed)
!12 = !{}
!13 = !DILocalVariable(name: "x", scope: !8, file: !1, line: 2, type: !11)
!14 = !DILocation(line: 2, column: 9, scope: !8)
!15 = !DILocation(line: 3, column: 5, scope: !8)
This has a number of features that our automatically-lowered LLVM-IR does not have including:
- !DICompileUnit
- !DIFile
- Dwarf Version
- !DISubprogram
- !DILocation
- !llvm.dbg.cu
- source_filename
- target datalayout
- target triple
It doesn’t surprise me that we don’t have some of these (like target triple, …) without doing extra work, but I’d have expected the location info to be converted into !DILocation.
It’s possible to emit DWARF info from an LLVM builder, which is how a non-MLIR project would do it. I have brutal hack of an example of that in my project — that program is a little standalone beastie that constructs equivalent LLVM-IR for a simulated C program. After MLIR lowering to LLVM-IR, I’m able to inject all the DI instrumentation (relying on the fact that I know the operations in this program, and the line numbers for those operations). It would be very difficult to do this in my toy-language compiler driver, since that has to work for all programs. It is totally and completely obvious that this is the WRONG way to do it. However, the little program is at least debuggable, and perhaps worth something for that reason.
We see the same sort of DI artifacts if we build a Fortran program with flang (not classic-flang, but MLIR flang):
program main
implicit none
integer :: x
x = 42
print *, x
end program main
The flang LL has all the expected DI elements:
; ModuleID = 'FIRModule'
source_filename = "FIRModule"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
$_QQclXc451cd8b1f5eae110b31be7df6c0fcf9 = comdat any
@_QQclXc451cd8b1f5eae110b31be7df6c0fcf9 = linkonce constant [43 x i8] c"/home/pjoot/toycalculator/fortran/test.f90\00", comdat
define void @_QQmain() #0 !dbg !6 {
%1 = alloca i32, i64 1, align 4, !dbg !9
#dbg_declare(ptr %1, !10, !DIExpression(), !9)
store i32 42, ptr %1, align 4, !dbg !12
%2 = call ptr @_FortranAioBeginExternalListOutput(i32 6, ptr @_QQclXc451cd8b1f5eae110b31be7df6c0fcf9, i32 5), !dbg !13
%3 = load i32, ptr %1, align 4, !dbg !14
%4 = call i1 @_FortranAioOutputInteger32(ptr %2, i32 %3), !dbg !14
%5 = call i32 @_FortranAioEndIoStatement(ptr %2), !dbg !13
ret void, !dbg !15
}
declare !dbg !16 ptr @_FortranAioBeginExternalListOutput(i32, ptr, i32)
declare !dbg !21 zeroext i1 @_FortranAioOutputInteger32(ptr, i32)
declare !dbg !25 i32 @_FortranAioEndIoStatement(ptr)
declare !dbg !28 void @_FortranAProgramStart(i32, ptr, ptr, ptr)
declare !dbg !31 void @_FortranAProgramEndStatement()
define i32 @main(i32 %0, ptr %1, ptr %2) #0 !dbg !33 {
call void @_FortranAProgramStart(i32 %0, ptr %1, ptr %2, ptr null), !dbg !36
call void @_QQmain(), !dbg !36
call void @_FortranAProgramEndStatement(), !dbg !36
ret i32 0, !dbg !36
}
attributes #0 = { "frame-pointer"="all" "target-cpu"="x86-64" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.dbg.cu = !{!3}
!llvm.ident = !{!5}
!0 = !{i32 2, !"Debug Info Version", i32 3}
!1 = !{i32 8, !"PIC Level", i32 2}
!2 = !{i32 7, !"PIE Level", i32 2}
!3 = distinct !DICompileUnit(language: DW_LANG_Fortran95, file: !4, producer: "flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)", isOptimized: false, runtimeVersion: 0, emissionKind: FullDebug)
!4 = !DIFile(filename: "test.f90", directory: "/home/pjoot/toycalculator/fortran")
!5 = !{!"flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)"}
!6 = distinct !DISubprogram(name: "main", linkageName: "_QQmain", scope: !4, file: !4, line: 1, type: !7, scopeLine: 1, spFlags: DISPFlagDefinition | DISPFlagMainSubprogram, unit: !3)
!7 = !DISubroutineType(cc: DW_CC_program, types: !8)
!8 = !{null}
!9 = !DILocation(line: 3, column: 14, scope: !6)
!10 = !DILocalVariable(name: "x", scope: !6, file: !4, line: 3, type: !11)
!11 = !DIBasicType(name: "integer", size: 32, encoding: DW_ATE_signed)
!12 = !DILocation(line: 4, column: 3, scope: !6)
!13 = !DILocation(line: 5, column: 3, scope: !6)
!14 = !DILocation(line: 5, column: 12, scope: !6)
!15 = !DILocation(line: 6, column: 1, scope: !6)
!16 = !DISubprogram(name: "_FortranAioBeginExternalListOutput", linkageName: "_FortranAioBeginExternalListOutput", scope: !4, file: !4, line: 5, type: !17, scopeLine: 5, spFlags: 0)
!17 = !DISubroutineType(cc: DW_CC_normal, types: !18)
!18 = !{!19, !11, !20, !11}
!19 = !DIDerivedType(tag: DW_TAG_pointer_type, baseType: !20, size: 64)
!20 = !DIBasicType(name: "integer", size: 8, encoding: DW_ATE_signed)
!21 = !DISubprogram(name: "_FortranAioOutputInteger32", linkageName: "_FortranAioOutputInteger32", scope: !4, file: !4, line: 5, type: !22, scopeLine: 5, spFlags: 0)
!22 = !DISubroutineType(cc: DW_CC_normal, types: !23)
!23 = !{!24, !20, !11}
!24 = !DIBasicType(name: "integer", size: 1, encoding: DW_ATE_signed)
!25 = !DISubprogram(name: "_FortranAioEndIoStatement", linkageName: "_FortranAioEndIoStatement", scope: !4, file: !4, line: 5, type: !26, scopeLine: 5, spFlags: 0)
!26 = !DISubroutineType(cc: DW_CC_normal, types: !27)
!27 = !{!11, !20}
!28 = !DISubprogram(name: "_FortranAProgramStart", linkageName: "_FortranAProgramStart", scope: !4, file: !4, line: 6, type: !29, scopeLine: 6, spFlags: 0)
!29 = !DISubroutineType(cc: DW_CC_normal, types: !30)
!30 = !{null, !11, !11, !11, !11}
!31 = !DISubprogram(name: "_FortranAProgramEndStatement", linkageName: "_FortranAProgramEndStatement", scope: !4, file: !4, line: 6, type: !32, scopeLine: 6, spFlags: 0)
!32 = !DISubroutineType(cc: DW_CC_normal, types: !8)
!33 = distinct !DISubprogram(name: "main", linkageName: "main", scope: !4, file: !4, line: 6, type: !34, scopeLine: 6, spFlags: DISPFlagDefinition, unit: !3)
!34 = !DISubroutineType(cc: DW_CC_normal, types: !35)
!35 = !{!11, !11, !11, !11}
!36 = !DILocation(line: 6, column: 1, scope: !33)
Ignoring all the language bootstrap gorp, this has all the expected DI elements, so we know that there’s a mechanism for flang to emit the DWARF instrumentation.
Looking through the flang source, the only place I found any sort of DI instrumentation was flang/lib/Optimizer/Transforms/AddDebugInfo.cpp, which, in about 600 lines, appears to implement all the DI instrumentation needed for variable and function declarations for the Fortran language (as a MLIR pass.) There’s nothing in there for location translation that I can see, except for a couple of little sneaky bits
bool debugInfoIsAlreadySet(mlir::Location loc) {
if (mlir::isa<mlir::FusedLoc>(loc)) {
if (loc->findInstanceOf<mlir::FusedLocWith<fir::LocationKindAttr>>())
return false;
return true;
}
return false;
}
...
declOp->setLoc(builder.getFusedLoc({declOp->getLoc()}, localVarAttr));
...
globalOp->setLoc(builder.getFusedLoc({globalOp.getLoc()}, arrayAttr));
...
void AddDebugInfoPass::handleFuncOp(mlir::func::FuncOp funcOp,
mlir::LLVM::DIFileAttr fileAttr,
mlir::LLVM::DICompileUnitAttr cuAttr,
fir::DebugTypeGenerator &typeGen,
mlir::SymbolTable *symbolTable) {
mlir::Location l = funcOp->getLoc();
// If fused location has already been created then nothing to do
// Otherwise, create a fused location.
if (debugInfoIsAlreadySet(l))
return;
...
// We have the imported entities now. Generate the final DISubprogramAttr.
spAttr = mlir::LLVM::DISubprogramAttr::get(
context, recId, /*isRecSelf=*/false, id2, compilationUnit, Scope,
funcName, fullName, funcFileAttr, line, line, subprogramFlags,
subTypeAttr, entities, /*annotations=*/{});
funcOp->setLoc(builder.getFusedLoc({l}, spAttr));
...
It looks as if a fused location is used to replace any MLIR supplied location for each function, but all the rest of the location info is left as is. My presumption is that translateModuleToLLVMIR() handles the plain old loc() references to !dbg. To get an idea what happens in AddDebugInfoPass, let’s look at the MLIR dump at the beginning, and compare to afterwards.
To see this, I used the following gdb script:
set follow-fork-mode child
set detach-on-fork off
set breakpoint pending on
break AddDebugInfoPass::runOnOperation
run
Here’s the debug session to see the module dumps before and after AddDebugInfoPass
fedora:/home/pjoot/toycalculator/fortran> gdb -q -x b --args /usr/local/llvm-20.1.5/bin/flang-new -g -S -emit-llvm test.f90 -o test.ll
...
[Switching to Thread 0x7fffda437640 (LWP 119612)]
Thread 2.1 "flang" hit Breakpoint 1.2, (anonymous namespace)::AddDebugInfoPass::runOnOperation (this=0x6368e0)
at /home/pjoot/llvm-project/flang/lib/Optimizer/Transforms/AddDebugInfo.cpp:520
520 mlir::ModuleOp module = getOperation();
(gdb) n
521 mlir::MLIRContext *context = &getContext();
(gdb) p module->dump()
module attributes {dlti.dl_spec = #dlti.dl_spec : vector<2xi64>, !llvm.ptr<270> = dense<32> : vector<4xi64>, f16 = dense<16> : vector<2xi64>, f64 = dense<64> : vector<2xi64>, i32 = dense<32> : vector<2xi64>, i16 = dense<16> : vector<2xi64>, i8 = dense<8> : vector<2xi64>, i1 = dense<8> : vector<2xi64>, !llvm.ptr = dense<64> : vector<4xi64>, f80 = dense<128> : vector<2xi64>, i128 = dense<128> : vector<2xi64>, i64 = dense<64> : vector<2xi64>, !llvm.ptr<271> = dense<32> : vector<4xi64>, !llvm.ptr<272> = dense<64> : vector<4xi64>, "dlti.endianness" = "little", "dlti.stack_alignment" = 128 : i64>, fir.defaultkind = "a1c4d8i4l4r4", fir.kindmap = "", fir.target_cpu = "x86-64", llvm.data_layout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128", llvm.ident = "flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)", llvm.target_triple = "x86_64-unknown-linux-gnu"} {
func.func @_QQmain() attributes {fir.bindc_name = "main"} {
%c5_i32 = arith.constant 5 : i32
%c6_i32 = arith.constant 6 : i32
%c42_i32 = arith.constant 42 : i32
%0 = fir.alloca i32 {bindc_name = "x", uniq_name = "_QFEx"}
%1 = fircg.ext_declare %0 {uniq_name = "_QFEx"} : (!fir.ref) -> !fir.ref
fir.store %c42_i32 to %1 : !fir.ref
%2 = fir.address_of(@_QQclXc451cd8b1f5eae110b31be7df6c0fcf9) : !fir.ref<!fir.char<1,43>>
%3 = fir.convert %2 : (!fir.ref<!fir.char<1,43>>) -> !fir.ref
%4 = fir.call @_FortranAioBeginExternalListOutput(%c6_i32, %3, %c5_i32) fastmath : (i32, !fir.ref, i32) -> !fir.ref
%5 = fir.load %1 : !fir.ref
%6 = fir.call @_FortranAioOutputInteger32(%4, %5) fastmath : (!fir.ref, i32) -> i1
%7 = fir.call @_FortranAioEndIoStatement(%4) fastmath : (!fir.ref) -> i32
return
}
func.func private @_FortranAioBeginExternalListOutput(i32, !fir.ref, i32) -> !fir.ref attributes {fir.io, fir.runtime}
fir.global linkonce @_QQclXc451cd8b1f5eae110b31be7df6c0fcf9 constant : !fir.char<1,43> {
%0 = fir.string_lit "/home/pjoot/toycalculator/fortran/test.f90\00"(43) : !fir.char<1,43>
fir.has_value %0 : !fir.char<1,43>
}
func.func private @_FortranAioOutputInteger32(!fir.ref, i32) -> i1 attributes {fir.io, fir.runtime}
func.func private @_FortranAioEndIoStatement(!fir.ref) -> i32 attributes {fir.io, fir.runtime}
func.func private @_FortranAProgramStart(i32, !llvm.ptr, !llvm.ptr, !llvm.ptr)
func.func private @_FortranAProgramEndStatement()
func.func @main(%arg0: i32, %arg1: !llvm.ptr, %arg2: !llvm.ptr) -> i32 {
%c0_i32 = arith.constant 0 : i32
%0 = fir.zero_bits !fir.ref<tuple<i32, !fir.ref<!fir.array<0xtuple<!fir.ref, !fir.ref>>>>>
fir.call @_FortranAProgramStart(%arg0, %arg1, %arg2, %0) fastmath : (i32, !llvm.ptr, !llvm.ptr, !fir.ref<tuple<i32, !fir.ref<!fir.array<0xtuple<!fir.ref, !fir.ref>>>>>) -> ()
fir.call @_QQmain() fastmath : () -> ()
fir.call @_FortranAProgramEndStatement() fastmath : () -> ()
return %c0_i32 : i32
}
}
(gdb) c
Continuing.
Thread 2.1 "flang" hit Breakpoint 3.2, Fortran::frontend::CodeGenAction::generateLLVMIR (this=0x485530) at /home/pjoot/llvm-project/flang/lib/Frontend/FrontendActions.cpp:889
889 timingScopeMLIRPasses.stop();
(gdb) mlirModule.op.dump()
module attributes {dlti.dl_spec = #dlti.dl_spec : vector<2xi64>, !llvm.ptr<270> = dense<32> : vector<4xi64>, f16 = dense<16> : vector<2xi64>, f64 = dense<64> : vector<2xi64>, i32 = dense<32> : vector<2xi64>, i16 = dense<16> : vector<2xi64>, i8 = dense<8> : vector<2xi64>, i1 = dense<8> : vector<2xi64>, !llvm.ptr = dense<64> : vector<4xi64>, f80 = dense<128> : vector<2xi64>, i128 = dense<128> : vector<2xi64>, i64 = dense<64> : vector<2xi64>, !llvm.ptr<271> = dense<32> : vector<4xi64>, !llvm.ptr<272> = dense<64> : vector<4xi64>, "dlti.endianness" = "little", "dlti.stack_alignment" = 128 : i64>, fir.defaultkind = "a1c4d8i4l4r4", fir.kindmap = "", fir.target_cpu = "x86-64", llvm.data_layout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128", llvm.ident = "flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)", llvm.target_triple = "x86_64-unknown-linux-gnu"} {
llvm.func @_QQmain() attributes {fir.bindc_name = "main", frame_pointer = #llvm.framePointerKind, target_cpu = "x86-64"} {
%0 = llvm.mlir.constant(1 : i64) : i64
%1 = llvm.alloca %0 x i32 {bindc_name = "x"} : (i64) -> !llvm.ptr
%2 = llvm.mlir.constant(5 : i32) : i32
%3 = llvm.mlir.constant(6 : i32) : i32
%4 = llvm.mlir.constant(42 : i32) : i32
%5 = llvm.mlir.constant(1 : i64) : i64
llvm.intr.dbg.declare #llvm.di_local_variable, id = distinct[1]<>, compileUnit = , sourceLanguage = DW_LANG_Fortran95, file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, producer = "flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)", isOptimized = false, emissionKind = Full>, scope = #llvm.di_file<"test.f90" in "/home/pjoot/toycalculator/fortran">, name = "main", linkageName = "_QQmain", file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, line = 1, scopeLine = 1, subprogramFlags = "Definition|MainSubprogram", type = >, name = "x", file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, line = 3, type = #llvm.di_basic_type> = %1 : !llvm.ptr
llvm.store %4, %1 : i32, !llvm.ptr
%6 = llvm.mlir.addressof @_QQclXc451cd8b1f5eae110b31be7df6c0fcf9 : !llvm.ptr
%7 = llvm.call @_FortranAioBeginExternalListOutput(%3, %6, %2) {fastmathFlags = #llvm.fastmath} : (i32, !llvm.ptr, i32) -> !llvm.ptr
%8 = llvm.load %1 : !llvm.ptr -> i32
%9 = llvm.call @_FortranAioOutputInteger32(%7, %8) {fastmathFlags = #llvm.fastmath} : (!llvm.ptr, i32) -> i1
%10 = llvm.call @_FortranAioEndIoStatement(%7) {fastmathFlags = #llvm.fastmath} : (!llvm.ptr) -> i32
llvm.return
}
llvm.func @_FortranAioBeginExternalListOutput(i32, !llvm.ptr, i32) -> !llvm.ptr attributes {fir.io, fir.runtime, frame_pointer = #llvm.framePointerKind, sym_visibility = "private", target_cpu = "x86-64"}
llvm.mlir.global linkonce constant @_QQclXc451cd8b1f5eae110b31be7df6c0fcf9() comdat(@__llvm_comdat::@_QQclXc451cd8b1f5eae110b31be7df6c0fcf9) {addr_space = 0 : i32} : !llvm.array<43 x i8> {
%0 = llvm.mlir.constant("/home/pjoot/toycalculator/fortran/test.f90\00") : !llvm.array<43 x i8>
llvm.return %0 : !llvm.array<43 x i8>
}
llvm.comdat @__llvm_comdat {
llvm.comdat_selector @_QQclXc451cd8b1f5eae110b31be7df6c0fcf9 any
}
llvm.func @_FortranAioOutputInteger32(!llvm.ptr, i32) -> (i1 {llvm.zeroext}) attributes {fir.io, fir.runtime, frame_pointer = #llvm.framePointerKind, sym_visibility = "private", target_cpu = "x86-64"}
llvm.func @_FortranAioEndIoStatement(!llvm.ptr) -> i32 attributes {fir.io, fir.runtime, frame_pointer = #llvm.framePointerKind, sym_visibility = "private", target_cpu = "x86-64"}
llvm.func @_FortranAProgramStart(i32, !llvm.ptr, !llvm.ptr, !llvm.ptr) attributes {frame_pointer = #llvm.framePointerKind, sym_visibility = "private", target_cpu = "x86-64"}
llvm.func @_FortranAProgramEndStatement() attributes {frame_pointer = #llvm.framePointerKind, sym_visibility = "private", target_cpu = "x86-64"}
llvm.func @main(%arg0: i32, %arg1: !llvm.ptr, %arg2: !llvm.ptr) -> i32 attributes {frame_pointer = #llvm.framePointerKind, target_cpu = "x86-64"} {
%0 = llvm.mlir.constant(0 : i32) : i32
%1 = llvm.mlir.zero : !llvm.ptr
llvm.call @_FortranAProgramStart(%arg0, %arg1, %arg2, %1) {fastmathFlags = #llvm.fastmath} : (i32, !llvm.ptr, !llvm.ptr, !llvm.ptr) -> ()
llvm.call @_QQmain() {fastmathFlags = #llvm.fastmath} : () -> ()
llvm.call @_FortranAProgramEndStatement() {fastmathFlags = #llvm.fastmath} : () -> ()
llvm.return %0 : i32
}
}
Even before the AddDebugInfoPass we have target_cpu, data_layout, ident, and target_triple set, so AddDebugInfoPass doesn’t add those. We do have all of these, either added by AddDebugInfoPass, or something after it:
llvm.intr.dbg.declare #llvm.di_local_variable, id = distinct[1]<>, compileUnit = , sourceLanguage = DW_LANG_Fortran95, file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, producer = "flang version 20.1.5 (https://github.com/llvm/llvm-project.git 7b09d7b446383b71b63d429b21ee45ba389c5134)", isOptimized = false, emissionKind = Full>, scope = #llvm.di_file<"test.f90" in "/home/pjoot/toycalculator/fortran">, name = "main", linkageName = "_QQmain", file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, line = 1, scopeLine = 1, subprogramFlags = "Definition|MainSubprogram", type = >, name = "x", file = <"test.f90" in "/home/pjoot/toycalculator/fortran">, line = 3, type = #llvm.di_basic_type> = %1 : !llvm.ptr
So, it looks like we need to add a compileUnit, subprogram, and if we want debug variables, instrumentation for those too.
In some standalone code (prototypes/simplest.cpp) adding those wasn’t enough to ensure that translateModuleToLLVMIR() didn’t strip out the location info.
What did make the difference was adding this bit:
func->setLoc( builder.getFusedLoc( { loc }, subprogramAttr ) );
with that, the generated LLVM-IR, not only doesn’t have the loc() stripped, but everything is properly converted to !dbg:
; ModuleID = 'test'
source_filename = "test"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
define i32 @main() !dbg !4 {
%1 = alloca i64, i64 1, align 4, !dbg !8
store i32 42, ptr %1, align 4, !dbg !8
#dbg_declare(ptr %1, !9, !DIExpression(), !8)
ret i32 0, !dbg !10
}
; Function Attrs: nocallback nofree nosync nounwind speculatable willreturn memory(none)
declare void @llvm.dbg.declare(metadata, metadata, metadata) #0
attributes #0 = { nocallback nofree nosync nounwind speculatable willreturn memory(none) }
!llvm.module.flags = !{!0}
!llvm.dbg.cu = !{!1}
!llvm.ident = !{!3}
!0 = !{i32 2, !"Debug Info Version", i32 3}
!1 = distinct !DICompileUnit(language: DW_LANG_C, file: !2, producer: "testcompiler", isOptimized: false, runtimeVersion: 0, emissionKind: FullDebug)
!2 = !DIFile(filename: "test.c", directory: ".")
!3 = !{!"toycompiler 0.0"}
!4 = distinct !DISubprogram(name: "main", linkageName: "main", scope: !2, file: !2, line: 1, type: !5, scopeLine: 1, spFlags: DISPFlagDefinition, unit: !1)
!5 = !DISubroutineType(types: !6)
!6 = !{!7}
!7 = !DIBasicType(name: "int", size: 32, encoding: DW_ATE_signed)
!8 = !DILocation(line: 2, column: 3, scope: !4)
!9 = !DILocalVariable(name: "x", scope: !4, file: !2, line: 2, type: !7, align: 32)
!10 = !DILocation(line: 3, column: 3, scope: !4)
I’m also able to debug a faked source file corresponding to the LLVM-IR generated by this MWE program:
fedora:/home/pjoot/toycalculator/prototypes> ../build/simplest > output.ll
fedora:/home/pjoot/toycalculator/prototypes> clang -g -o output output.ll -Wno-override-module
fedora:/home/pjoot/toycalculator/prototypes> gdb -q ./output
Reading symbols from ./output...
(gdb) b main
Breakpoint 1 at 0x400450: file test.c, line 2.
(gdb) run
Starting program: /home/pjoot/toycalculator/prototypes/output
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Breakpoint 1, main () at test.c:2
2 int x = 42;
(gdb) n
3 return 0;
(gdb) p x
$1 = 42
(gdb) rerun
Undefined command: "rerun". Try "help".
(gdb) run
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/pjoot/toycalculator/prototypes/output
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Breakpoint 1, main () at test.c:2
2 int x = 42;
(gdb) b 3
Breakpoint 2 at 0x400458: file test.c, line 3.
(gdb) c
Continuing.
Breakpoint 2, main () at test.c:3
3 return 0;
(gdb) q
A debugging session is active.
Inferior 1 [process 119835] will be killed.
Quit anyway? (y or n) y
Now that I have this working in a standalone test case, it’s time to do it in the toy compiler itself, but that’s a task for another day.
Like this:
Like Loading...