Today I received the following Remembrance day message at work:
“Every year on November 11th, Canadians pause for a moment of silence in remembrance of the men and women who have served our country during times of war, conflict and peace. More than 1,500,000 Canadians have served our country in this way and over 100,000 have paid the ultimate sacrifice.
They gave their lives and their futures for the freedoms we enjoy today.
At 11:00 a.m. today, please join me in observing one full minute of silence.
“
This illustrates precisely the sort of propaganda that is buried in this yearly celebration of war. Many people will object to my labeling of Remembrance day as a celebration of war, but I think that is an apt label.
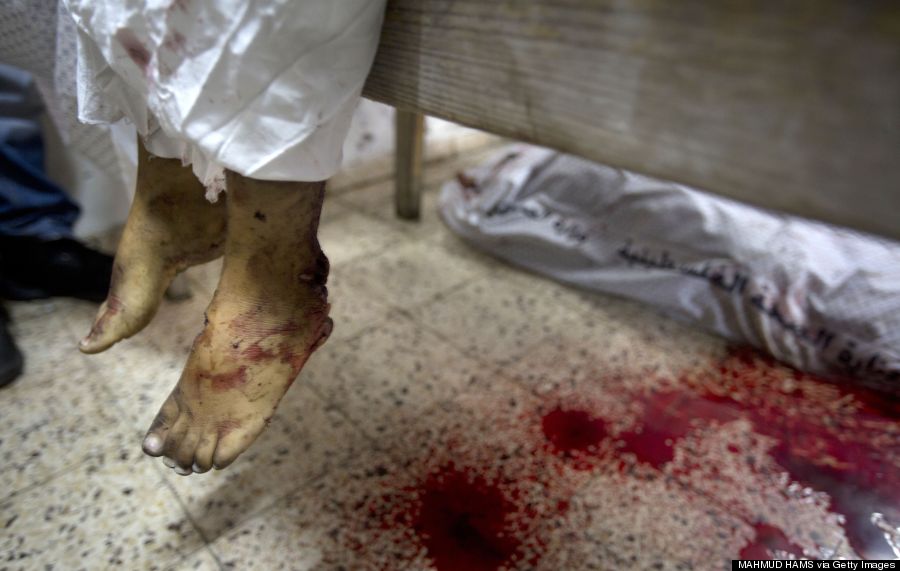
We should remember the collective insanity that drove so many to send themselves off to be killed or kill. We should remember those who profited from the wars, and those who funded both sided. Let’s remember the Carnegies who concluded that there’s no better industry than war for profits and pleaded to Wilson to not end world war I too quickly. We should remember the massive propaganda campaigns to attempt to coerce people into fighting these wars. We should remember the disgusting lies that have been used again and again to justify wars that are later proven false. We should remember the US companies like Ford and IBM (my current employer!) that provided financial and resource backing to Hitler, without which his final atrocities would not have been possible. We should remember how every war has been an excuse for raising taxes to new peaks, raising nationalistic debt servitude at every turn (*). We should remember that civilians are the people most hurt by wars, and not focus our attentions on those soldiers that held the guns or were shot by them.
There are many things to remember, and if we are deluded into focusing our attention on the “sacrifices of soldiers”, who are pawns in the grand scheme of things, then we loose.
It is interesting to see just how transparent the Remembrance day propaganda can be. It is not just the glorification of the soldiers who were killed and did their killing. We are asked specifically to also glorify the people that “serve” Canada in it’s day to day waging of what amounts to US imperialistic warfare in times of peace.
Ron Paul’s recent commentary on Canada’s current war mongering nature was very apt. We should remember that the aggressions that happen in our names have consequences.
If it were not for acceptance of the sorts of patriotic drivel that we see on Remembrance day, and patriotism conditioning events like the daily standing for the national anthem, perhaps a few less people would be so willing to fight wars for or against governments that are not worth obeying.
We give governments power by sheepish compliance. This service is to an entity that is a figment of our collective agreement.
Today I’ll actually just remember my dad. He is the only person I knew that saw through the social conditioning of Remembrance day and so aptly identified it as a propaganda event.
Footnotes:
(*) I’m not sure how definitive the debtclock link above is, nor it’s sources. Here’s a newer Canadian debt-clock. That site is currently also vague about it’s sources, citing “Canadian Government Data” without specifying them, nor linking to them.

{kind=link}