I’ve achieved a new pinnacle of obscurity, and have now written a rudimentary COBOL implementation of a geometric algebra library for \( \mathbb{R}^2 \) calculations.
Who will use this? Absolutely nobody. Effectively, nobody knows geometric algebra. Nobody wants to know COBOL, but some do. The union of those two groups is vanishingly small (probably one: argued below.)
I understand that some Opus Dei members have taught themselves COBOL, as looking at COBOL has been found to be equally painful as a course of self flagellation.

Figure 0. A flagellation representation of COBOL.
Assuming that no Opus Dei practitioners know geometric algebra, that means that there is exactly one person in the world that both knows COBOL and geometric algebra. Me.
Why did I write this little library? Well, I was tickled to write something so completely stupid, and I’ve been laughing at the absurdity of it. I also thought I might learn a few things about COBOL in the process of trying to use it for something slightly non-trivial. I’m adept at writing simple test programs that exercise various obscure compiler features, but those are usually fairly small. On the flip side of complexity, I have to debug through a number of horribly complicated customer programs as part of my compiler validation work. A simple real life test scenario might run 100+ COBOL programs in a set of CICS transactions, executing thousands of EXEC DLI and EXEC CICS statements as well as all of the rest of the COBOL language statements! Despite having gained familiarity with COBOL from that sort of observational use, walking through stuff in the debugger doesn’t provide the same level of comfort with the language as writing code from scratch. Since I have no interest in simulating a boring business application, why not do something just for fun as a learning game.
The compiler I am using does not seem to support object-COBOL (which would have been nicely suited for this project), so I’ve written my little toy in conventional COBOL, using one external procedure for each type of mathematical operation. In the huge set of customer COBOL code that I’ve examined and done test compilations of, none of it has used object-COBOL. I am guessing that the object-COBOL community is as large as the user base for my little toy COBOL geometric algebra library will ever be.
I’ve implemented methods to construct multivectors with scalar, vector and pseudoscalar components, or a general multivector with all of the above. I’ve also implemented multiply, add, subtract, scalar multiplication, grade selection, and a DISPLAY function to write a multivector to SYSOUT (stdout equivalent.)
The multivector “type”
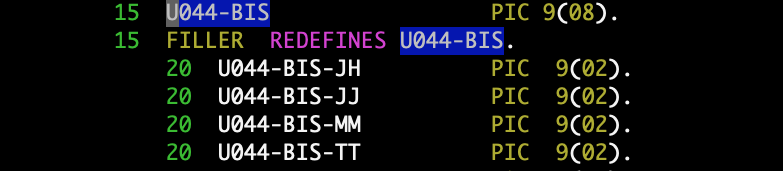
Figure 1 shows the implementation of my multivector type, implemented in copybook (include file) named MVI. I have an alternate MV copybook that doesn’t have the VALUE (initialization) clauses, as you don’t want initialization for LINKAGE-SECTION values (i.e.: program parameters.)

Figure 1. Copybook with multivector declaration and initialization.
If you are wondering what the hell a ‘PIC S9(9) USAGE IS COMP-5’ is, well, that’s the “easy to remember” way to declare a 32-bit signed integer in COBOL. A COMP-2, on the other hand, is a floating point value.
Figure 2 shows an example of the use of this copybook:

Figure 2. Using the multivector copybook.
Figure 3 shows these two copybook declarations after preprocessor expansion

Figure 3. Multivector global variable examples after preprocessing.
The global variable declarations above are roughly equivalent to the following pseudo C++ code (pretending that we can have anonymous unions that match the COBOL declarations above):
#include <complex>
using complex = std::complex<double>;
struct ga20{
int grade{};
union {
struct { double sc{}; double ps{}; };
complex g02{};
};
union {
struct { double x{}; double y{}; };
complex g1{};
};
};
ga20 a;
ga20 b;
COBOL is inherently untyped, but requires matching types for CALL parameters, or else all hell ensues, so you have to rely on naming conventions and other mechanisms to enforce the required type equivalences. In this toy GA library, I’ve used copybooks to enforce the types required for everything. Global variable declarations like these A-MV and B-MV variables are declared only using a copybook that knows the representation required, and all the uses in sub-programs of the effective -MV “type” use a matching copybook for their declarations. However, I’ve also made use of the lack of typing to treat A-G02, B-G02, A-G1, and B-G1 as if they were complex numbers, and pass those “variables” off to complex number sub-programs, knowing that I’ve constructed the parameters to those programs in a way that is bit compatible with the MV field values. You can screw things up really nicely doing stuff like this, especially because all COBOL sub-program parameters are (generally) passed by reference. If you don’t match up the types right “fun ensues.”
Also observe that the nested level specifiers are optional in COBOL. For nested fields in C++, we might write a.g1.x. With a nested variable like this in COBOL, we could write something equivalent to that, like:
A-X OF A-G1 OF A-MV
but we can leave out any of the intermediate “level” specifications if we want. This gets really confusing in complicated real-life COBOL code. If you are looking to see where something is modified, you have to not only look for the variable of interest, but also any of the higher level fields, since any of those could have been passed off to other code, which implicitly wrote the value you are interested in.
Here’s what one of these multivectors looks like in memory on my (Linux x86-64) system
(lldb) c
Process 3903259 resuming
Process 3903259 stopped
* thread #10, name = 'GA20', stop reason = breakpoint 7.1
frame #0: 0x00007fffd9189a02 PJOOT.GA20V01.LOADLIB(MULT).ec73dc4b`MULT at MULT.cob:50:1
47 CALL GA-MKVECTOR-MODIFY USING C-MV, A-X, A-Y
48 CALL GA-MKPSEUDO-MODIFY USING D-MV, A-PS
49
-> 50 MOVE 'A' TO WS-DISPPARM-N
51 CALL GA-DISPLAY USING
52 WS-DISPPARM-N,
53 A-MV
(lldb) p A-MV
(A-MV) A-MV = {
A-GRADE = -1
A-G02 = (A-SC = 1, A-PS = 4)
A-G1 = (A-X = 2, A-Y = 3)
}
i.e.: this has the value \( 1 + 2 \mathbf{e}_{12} + 3 \mathbf{e}_1 + 4 \mathbf{e}_1 \).
Looking at the multivector in it’s hex representation:
(lldb) fr v -format x A-MV
(A-MV) A-MV = {
A-GRADE = 0xffffffff
A-G02 = {
A-SC = 0x3ff0000000000000
A-PS = 0x4010000000000000
}
A-G1 = {
A-X = 0x4000000000000000
A-Y = 0x4008000000000000
}
}
we see that the debugger is showing an underlying IEEE floating point representation for the COMP-2 variables in the program as it was compiled.
I have a multivector print routine that prints multivectors to SYSOUT:

Figure 4. Calling the multivector DISPLAY function.
where WS-DISPPARM-N is a PIC X(20). (i.e.: a fixed size character array.) Output for the A-MV value showing in the debug session above looks like:
A ( .10000000000000000E 01)
+ ( .20000000000000000E 01) e_1 + ( .30000000000000000E 01) e_2
+ ( .40000000000000000E 01) e_{12}
End of sentence required for nested IFs?
I encountered a curious language issue in my multivector multiply function. Here’s an example of how I’ve been coding IF statements

Figure 5. An IF END-IF pair without a period to terminate the sentence.
Notice that I don’t do anything special between the END-IF and the statement that follows it. However, if I have an IF statement that includes nested IF END-IFs, then it appears that I need a period after the final END-IF, like so:

Figure 6. An IF with nested conditions that seems to require a period to terminate the sentence.
If I don’t include that period after the final END-IF (ending the COBOL sentence), then in some circumstances, I was seeing the program exit after the last interior basic block within this nested IF was executed. In COBOL parlance, it seems as if a GOBACK (i.e.: return) was implicitly executed once we fell out of the big nested IF. Why is that period required for a nested IF, but not for a simple IF?
In my “Murach’s mainframe COBOL”, he ends ALL if statements with a period, even simple IFs. I don’t see a rationale for that in the book anywhere, but it’s a ~700 page book, so perhaps he says why at some point.
I’ve asked our compiler guys if this is a bug or expected behaviour, but I am guessing the latter…. I just don’t know why.
The multiplication kernel for this library
The workhorse of this GA(2,0) implementation, is a multivector multiplication operation, which can be implemented in two lines in Mathematica (or C++)
multivector /: multivector[_, m1_, m2_] ** multivector[_, n1_, n2_] := multivector[-1, m1 n1 + Conjugate[m2] n2, n1 m2 + Conjugate[m1] n2 ]
In COBOL, it takes a lot more, and as usual, COBOL verbosity obfuscates things considerably. Here’s the equivalent code in my library:

Figure 7. GA(2,0) multiplication kernel in COBOL.
The library and a little test program.
If you are curious, you can poke around in the code for this library and the test program on github. The sample/test program is src/MULT.cob, and running the job gives the following SYSOUT:

Figure 8. Sample SYSOUT for MULT.cob