[Click here for a PDF of this post with nicer formatting]
Motivation.
In my old classical mechanics notes it appears that I did covariant derivations of the Lorentz force equations a number of times, using different trial Lagrangians (relativistic and non-relativistic), and using both geometric algebra and tensor methods. However, none of these appear to have been done concisely, and a number not even coherently.
The following document has been drafted as replacement text for those incoherent classical mechanics notes. I’ll attempt to cover
- a lighting review of the geometric algebra STA (Space Time Algebra),
- relations between Dirac matrix algebra and STA,
- derivation of the relativistic form of the Euler-Lagrange equations from the covariant form of the action,
- relationship of the STA form of the Euler-Lagrange equations to their tensor equivalents,
- derivation of the Lorentz force equation from the STA Lorentz force Lagrangian,
- relationship of the STA Lorentz force equation to its equivalent in the tensor formalism,
- relationship of the STA Lorentz force equation to the traditional vector form.
Note that some of the prerequisite ideas and auxiliary details are presented as problems with solutions. If the reader has sufficient background to attempt those problems themselves, they are encouraged to do so.
The STA and geometric algebra ideas used here are not complete to learn from in isolation. The reader is referred to [1] for a more complete exposition of both STA and geometric algebra.
Conventions.
Definition 1.1: Index conventions.
Latin indexes \( i, j, k, r, s, t, \cdots \) are used to designate values in the range \( \setlr{ 1,2,3 } \). Greek indexes are \( \alpha, \beta, \mu, \nu, \cdots \) are used for indexes of spacetime quantities \( \setlr{0,1,2,3} \).
The Einstein convention of implied summation for mixed upper and lower Greek indexes will be used, for example
\begin{equation*}
x^\alpha x_\alpha \equiv \sum_{\alpha = 0}^3 x^\alpha x_\alpha.
\end{equation*}
Space Time Algebra (STA.)
In the geometric algebra literature, the Dirac algebra of quantum field theory has been rebranded Space Time Algebra (STA). The differences between STA and the Dirac theory that uses matrices (\( \gamma_\mu \)) are as follows
- STA completely omits any representation of the Dirac basis vectors \( \gamma_\mu \). In particular, any possible matrix representation is irrelevant.
- STA provides a rich set of fundamental operations (grade selection, generalized dot and wedge products for multivector elements, rotation and reflection operations, …)
- Matrix trace, and commutator and anticommutator operations are nowhere to be found in STA, as geometrically grounded equivalents are available instead.
- The “slashed” quantities from Dirac theory, such as \( \gamma_\mu p^\mu \) are nothing more than vectors in their entirety in STA (where the basis is no longer implicit, as is the case for coordinates.)
Our basis vectors have the following properties.
Definition 1.2: Standard basis.
Let the four-vector standard basis be designated \( \setlr{\gamma_0, \gamma_1, \gamma_2, \gamma_3 } \), where the basis vectors satisfy
\begin{equation}\label{eqn:lorentzForceCovariant:1540}
\begin{aligned}
\gamma_0^2 &= -\gamma_i^2 = 1 \\
\gamma_\alpha \cdot \gamma_\beta &= 0, \forall \alpha \ne \beta.
\end{aligned}
\end{equation}
Problem: Commutator properties of the STA basis.
In Dirac theory, the commutator properties of the Dirac matrices is considered fundamental, namely
\begin{equation*}
\symmetric{\gamma_\mu}{\gamma_\nu} = 2 \eta_{\mu\nu}.
\end{equation*}
Show that this follows from the axiomatic assumptions of geometric algebra, and describe how the dot and wedge products are related to the anticommutator and commutator products of Dirac theory.
Answer
The anticommutator is defined as symmetric sum of products
\begin{equation}\label{eqn:lorentzForceCovariant:1040}
\symmetric{\gamma_\mu}{\gamma_\nu}
\equiv
\gamma_\mu \gamma_\nu
+
\gamma_\nu \gamma_\mu,
\end{equation}
but this is just twice the dot product in its geometric algebra form \( a b = (a b + ba)/2 \). Observe that the properties of the basis vectors defined in \ref{eqn:lorentzForceCovariant:1540} may be summarized as
\begin{equation}\label{eqn:lorentzForceCovariant:1060}
\gamma_\mu \cdot \gamma_\nu = \eta_{\mu\nu},
\end{equation}
where \( \eta_{\mu\nu} = \text{diag}(+,-,-,-)
=
\begin{bmatrix}
1 & 0 & 0 & 0 \\
0 & -1 & 0 & 0 \\
0 & 0 & -1 & 0 \\
0 & 0 & 0 & -1 \\
\end{bmatrix}
\) is the conventional metric tensor. This means
\begin{equation}\label{eqn:lorentzForceCovariant:1080}
\gamma_\mu \cdot \gamma_\nu = \eta_{\mu\nu} = 2 \symmetric{\gamma_\mu}{\gamma_\nu},
\end{equation}
as claimed.
Similarly, observe that the commutator, defined as the antisymmetric sum of products
\begin{equation}\label{eqn:lorentzForceCovariant:1100}
\antisymmetric{\gamma_\mu}{\gamma_\nu} \equiv
\gamma_\mu \gamma_\nu
–
\gamma_\nu \gamma_\mu,
\end{equation}
is twice the wedge product \( a \wedge b = (a b – b a)/2 \). This provides geometric identifications for the respective anti-commutator and commutator products respectively
\begin{equation}\label{eqn:lorentzForceCovariant:1120}
\begin{aligned}
\symmetric{\gamma_\mu}{\gamma_\nu} &= 2 \gamma_\mu \cdot \gamma_\nu \\
\antisymmetric{\gamma_\mu}{\gamma_\nu} &= 2 \gamma_\mu \wedge \gamma_\nu,
\end{aligned}
\end{equation}
Definition 1.3: Pseudoscalar.
The pseudoscalar for the space is denoted \( I = \gamma_0 \gamma_1 \gamma_2 \gamma_3 \).
Problem: Pseudoscalar.
Show that the STA pseudoscalar \( I \) defined by \ref{eqn:lorentzForceCovariant:1540} satisfies
\begin{equation*}
\tilde{I} = I,
\end{equation*}
where the tilde operator designates reversion. Also show that \( I \) has the properties of an imaginary number
\begin{equation*}
I^2 = -1.
\end{equation*}
Finally, show that, unlike the spatial pseudoscalar that commutes with all grades, \( I \) anticommutes with any vector or trivector, and commutes with any bivector.
Answer
Since \( \gamma_\alpha \gamma_\beta = -\gamma_\beta \gamma_\alpha \) for any \( \alpha \ne \beta \), any permutation of the factors of \( I \) changes the sign once. In particular
\begin{equation}\label{eqn:lorentzForceCovariant:680}
\begin{aligned}
I &=
\gamma_0
\gamma_1
\gamma_2
\gamma_3 \\
&=
–
\gamma_1
\gamma_2
\gamma_3
\gamma_0 \\
&=
–
\gamma_2
\gamma_3
\gamma_1
\gamma_0 \\
&=
+
\gamma_3
\gamma_2
\gamma_1
\gamma_0
= \tilde{I}.
\end{aligned}
\end{equation}
Using this, we have
\begin{equation}\label{eqn:lorentzForceCovariant:700}
\begin{aligned}
I^2
&= I \tilde{I} \\
&=
(
\gamma_0
\gamma_1
\gamma_2
\gamma_3
)(
\gamma_3
\gamma_2
\gamma_1
\gamma_0
) \\
&=
\lr{\gamma_0}^2
\lr{\gamma_1}^2
\lr{\gamma_2}^2
\lr{\gamma_3}^2 \\
&=
(+1)
(-1)
(-1)
(-1) \\
&= -1.
\end{aligned}
\end{equation}
To illustrate the anticommutation property with any vector basis element, consider the following two examples:
\begin{equation}\label{eqn:lorentzForceCovariant:720}
\begin{aligned}
I \gamma_0 &=
\gamma_0
\gamma_1
\gamma_2
\gamma_3
\gamma_0 \\
&=
–
\gamma_0
\gamma_0
\gamma_1
\gamma_2
\gamma_3 \\
&=
–
\gamma_0 I,
\end{aligned}
\end{equation}
\begin{equation}\label{eqn:lorentzForceCovariant:740}
\begin{aligned}
I \gamma_2
&=
\gamma_0
\gamma_1
\gamma_2
\gamma_3
\gamma_2 \\
&=
–
\gamma_0
\gamma_1
\gamma_2
\gamma_2
\gamma_3 \\
&=
–
\gamma_2
\gamma_0
\gamma_1
\gamma_2
\gamma_3 \\
&= -\gamma_2 I.
\end{aligned}
\end{equation}
A total of three sign swaps is required to “percolate” any given \(\gamma_\alpha\) through the factors of \( I \), resulting in an overall sign change of \( -1 \).
For any bivector basis element \( \alpha \ne \beta \)
\begin{equation}\label{eqn:lorentzForceCovariant:760}
\begin{aligned}
I \gamma_\alpha \gamma_\beta
&=
-\gamma_\alpha I \gamma_\beta \\
&=
+\gamma_\alpha \gamma_\beta I.
\end{aligned}
\end{equation}
Similarly for any trivector basis element \( \alpha \ne \beta \ne \sigma \)
\begin{equation}\label{eqn:lorentzForceCovariant:780}
\begin{aligned}
I \gamma_\alpha \gamma_\beta \gamma_\sigma
&=
-\gamma_\alpha I \gamma_\beta \gamma_\sigma \\
&=
+\gamma_\alpha \gamma_\beta I \gamma_\sigma \\
&=
-\gamma_\alpha \gamma_\beta \gamma_\sigma I.
\end{aligned}
\end{equation}
Definition 1.4: Reciprocal basis.
The reciprocal basis \( \setlr{ \gamma^0, \gamma^1, \gamma^2, \gamma^3 } \) is defined , such that the property \( \gamma^\alpha \cdot \gamma_\beta = {\delta^\alpha}_\beta \) holds.
Observe that, \( \gamma^0 = \gamma_0 \) and \( \gamma^i = -\gamma_i \).
Theorem 1.1: Coordinates.
Coordinates are defined in terms of dot products with the standard basis, or reciprocal basis
\begin{equation*}
\begin{aligned}
x^\alpha &= x \cdot \gamma^\alpha \\
x_\alpha &= x \cdot \gamma_\alpha,
\end{aligned}
\end{equation*}
Start proof:
Suppose that a coordinate representation of the following form is assumed
\begin{equation}\label{eqn:lorentzForceCovariant:820}
x = x^\alpha \gamma_\alpha = x_\beta \gamma^\beta.
\end{equation}
We wish to determine the representation of the \( x^\alpha \) or \( x_\beta \) coordinates in terms of \( x\) and the basis elements. Taking the dot product with any standard basis element, we find
\begin{equation}\label{eqn:lorentzForceCovariant:840}
\begin{aligned}
x \cdot \gamma_\mu
&= (x_\beta \gamma^\beta) \cdot \gamma_\mu \\
&= x_\beta {\delta^\beta}_\mu \\
&= x_\mu,
\end{aligned}
\end{equation}
as claimed. Similarly, dotting with a reciprocal frame vector, we find
\begin{equation}\label{eqn:lorentzForceCovariant:860}
\begin{aligned}
x \cdot \gamma^\mu
&= (x^\beta \gamma_\beta) \cdot \gamma^\mu \\
&= x^\beta {\delta_\beta}^\mu \\
&= x^\mu.
\end{aligned}
\end{equation}
End proof.
Observe that raising or lowering the index of a spatial index toggles the sign of a coordinate, but timelike indexes are left unchanged.
\begin{equation}\label{eqn:lorentzForceCovariant:880}
\begin{aligned}
x^0 &= x_0 \\
x^i &= -x_i \\
\end{aligned}
\end{equation}
Definition 1.5: Spacetime gradient.
The spacetime gradient operator is
\begin{equation*}
\grad = \gamma^\mu \partial_\mu = \gamma_\nu \partial^\nu,
\end{equation*}
where
\begin{equation*}
\partial_\mu = \PD{x^\mu}{},
\end{equation*}
and
\begin{equation*}
\partial^\mu = \PD{x_\mu}{}.
\end{equation*}
This definition of gradient is consistent with the Dirac gradient (sometimes denoted as a slashed \(\partial\)).
Definition 1.6: Timelike and spacelike components of a four-vector.
Given a four vector \( x = \gamma_\mu x^\mu \), that would be designated \( x^\mu = \setlr{ x^0, \Bx} \) in conventional special relativity, we write
\begin{equation*}
x^0 = x \cdot \gamma_0,
\end{equation*}
and
\begin{equation*}
\Bx = x \wedge \gamma_0,
\end{equation*}
or
\begin{equation*}
x = (x^0 + \Bx) \gamma_0.
\end{equation*}
The spacetime split of a four-vector \( x \) is relative to the frame. In the relativistic lingo, one would say that it is “observer dependent”, as the same operations with \( {\gamma_0}’ \), the timelike basis vector for a different frame, would yield a different set of coordinates.
While the dot and wedge products above provide an effective mechanism to split a four vector into a set of timelike and spacelike quantities, the spatial component of a vector has a bivector representation in STA. Consider the following coordinate expansion of a spatial vector
\begin{equation}\label{eqn:lorentzForceCovariant:1000}
\Bx =
x \wedge \gamma_0
=
\lr{ x^\mu \gamma_\mu } \wedge \gamma_0
=
\sum_{k = 1}^3 x^k \gamma_k \gamma_0.
\end{equation}
Definition 1.7: Spatial basis.
We designate
\begin{equation}\label{eqn:lorentzForceCovariant:1560}
\Be_i = \gamma_i \gamma_0,
\end{equation}
as the standard basis vectors for \(\mathbb{R}^3\).
In the literature, this bivector representation of the spatial basis may be designated \( \sigma_i = \gamma_i \gamma_0 \), as these bivectors have the properties of the Pauli matrices \( \sigma_i \). Because I intend to expand these notes to include purely non-relativistic applications, I won’t use the Pauli notation here.
Problem: Orthonormality of the spatial basis.
Show that the spatial basis \( \setlr{ \Be_1, \Be_2, \Be_3 } \), defined by \ref{eqn:lorentzForceCovariant:1560}, is orthonormal.
Answer
\begin{equation}\label{eqn:lorentzForceCovariant:620}
\begin{aligned}
\Be_i \cdot \Be_j
&= \gpgradezero{ \gamma_i \gamma_0 \gamma_j \gamma_0 } \\
&= -\gpgradezero{ \gamma_i \gamma_j } \\
&= – \gamma_i \cdot \gamma_j.
\end{aligned}
\end{equation}
This is zero for all \( i \ne j \), and unity for any \( i = j \).
Problem: Spatial pseudoscalar.
Show that the STA pseudoscalar \( I = \gamma_0 \gamma_1 \gamma_2 \gamma_3 \) equals the spatial pseudoscalar \( I = \Be_1 \Be_2 \Be_3 \).
Answer
The spatial pseudoscalar, expanded in terms of the STA basis vectors, is
\begin{equation}\label{eqn:lorentzForceCovariant:1020}
\begin{aligned}
I
&= \Be_1 \Be_2 \Be_3 \\
&= \lr{ \gamma_1 \gamma_0 }
\lr{ \gamma_2 \gamma_0 }
\lr{ \gamma_3 \gamma_0 } \\
&= \lr{ \gamma_1 \gamma_0 } \gamma_2 \lr{ \gamma_0 \gamma_3 } \gamma_0 \\
&= \lr{ -\gamma_0 \gamma_1 } \gamma_2 \lr{ -\gamma_3 \gamma_0 } \gamma_0 \\
&= \gamma_0 \gamma_1 \gamma_2 \gamma_3 \lr{ \gamma_0 \gamma_0 } \\
&= \gamma_0 \gamma_1 \gamma_2 \gamma_3,
\end{aligned}
\end{equation}
as claimed.
Problem: Characteristics of the Pauli matrices.
The Pauli matrices obey the following anticommutation relations:
\begin{equation}\label{eqn:lorentzForceCovariant:660}
\symmetric{ \sigma_a}{\sigma_b } = 2 \delta_{a b},
\end{equation}
and commutation relations:
\begin{equation}\label{eqn:lorentzForceCovariant:640}
\antisymmetric{ \sigma_a}{ \sigma_b } = 2 i \epsilon_{a b c}\,\sigma_c,
\end{equation}
Show how these relate to the geometric algebra dot and wedge products, and determine the geometric algebra representation of the imaginary \( i \) above.
Euler-Lagrange equations.
I’ll start at ground zero, with the derivation of the relativistic form of the Euler-Lagrange equations from the action. A relativistic action for a single particle system has the form
\begin{equation}\label{eqn:lorentzForceCovariant:20}
S = \int d\tau L(x, \dot{x}),
\end{equation}
where \( x \) is the spacetime coordinate, \( \dot{x} = dx/d\tau \) is the four-velocity, and \( \tau \) is proper time.
Theorem 1.2: Relativistic Euler-Lagrange equations.
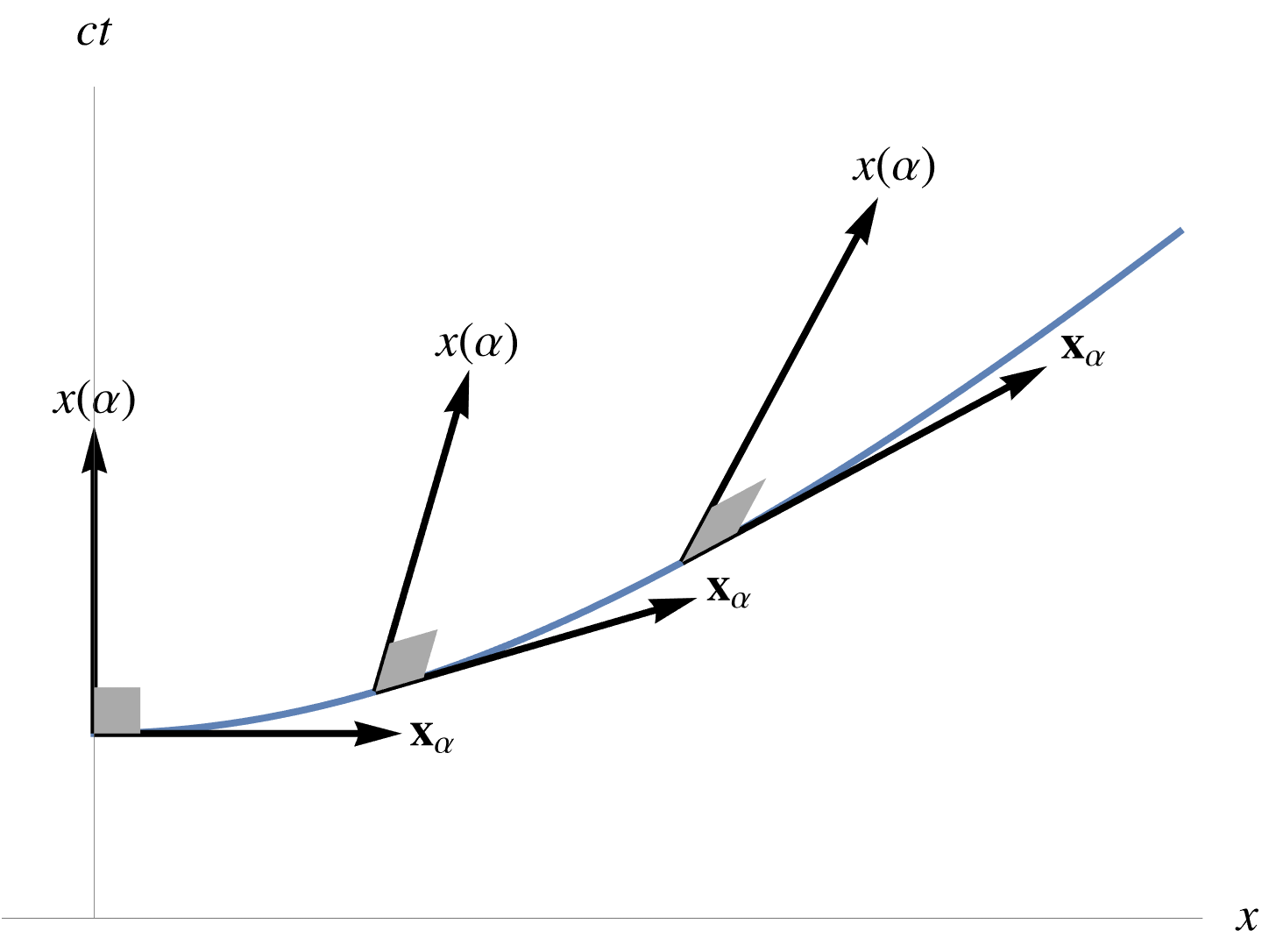
Let \( x \rightarrow x + \delta x \) be any variation of the Lagrangian four-vector coordinates, where \( \delta x = 0 \) at the boundaries of the action integral. The variation of the action is
\begin{equation}\label{eqn:lorentzForceCovariant:1580}
\delta S = \int d\tau \delta x \cdot \delta L(x, \dot{x}),
\end{equation}
where
\begin{equation}\label{eqn:lorentzForceCovariant:1600}
\delta L = \grad L – \frac{d}{d\tau} (\grad_v L),
\end{equation}
where \( \grad = \gamma^\mu \partial_\mu \), and where we construct a similar velocity-gradient with respect to the proper-time derivatives of the coordinates \( \grad_v = \gamma^\mu \partial/\partial \dot{x}^\mu \).The action is extremized when \( \delta S = 0 \), or when \( \delta L = 0 \). This latter condition is called the Euler-Lagrange equations.
Start proof:
Let \( \epsilon = \delta x \), and expand the Lagrangian in Taylor series to first order
\begin{equation}\label{eqn:lorentzForceCovariant:60}
\begin{aligned}
S &\rightarrow S + \delta S \\
&= \int d\tau L( x + \epsilon, \dot{x} + \dot{\epsilon})
&=
\int d\tau \lr{
L(x, \dot{x}) + \epsilon \cdot \grad L + \dot{\epsilon} \cdot \grad_v L
}.
\end{aligned}
\end{equation}
Subtracting off \( S \) and integrating by parts, leaves
\begin{equation}\label{eqn:lorentzForceCovariant:80}
\delta S =
\int d\tau \epsilon \cdot \lr{
\grad L – \frac{d}{d\tau} \grad_v L
}
+
\int d\tau \frac{d}{d\tau} (\grad_v L ) \cdot \epsilon.
\end{equation}
The boundary integral
\begin{equation}\label{eqn:lorentzForceCovariant:100}
\int d\tau \frac{d}{d\tau} (\grad_v L ) \cdot \epsilon
=
\evalbar{(\grad_v L ) \cdot \epsilon}{\Delta \tau} = 0,
\end{equation}
is zero since the variation \( \epsilon \) is required to vanish on the boundaries. So, if \( \delta S = 0 \), we must have
\begin{equation}\label{eqn:lorentzForceCovariant:120}
0 =
\int d\tau \epsilon \cdot \lr{
\grad L – \frac{d}{d\tau} \grad_v L
},
\end{equation}
for all variations \( \epsilon \). Clearly, this requires that
\begin{equation}\label{eqn:lorentzForceCovariant:140}
\delta L = \grad L – \frac{d}{d\tau} (\grad_v L) = 0,
\end{equation}
or
\begin{equation}\label{eqn:lorentzForceCovariant:145}
\grad L = \frac{d}{d\tau} (\grad_v L),
\end{equation}
which is the coordinate free statement of the Euler-Lagrange equations.
End proof.
Problem: Coordinate form of the Euler-Lagrange equations.
Working in coordinates, use the action argument show that the Euler-Lagrange equations have the form
\begin{equation*}
\PD{x^\mu}{L} = \frac{d}{d\tau} \PD{\dot{x}^\mu}{L}
\end{equation*}
Observe that this is identical to the statement of \ref{eqn:lorentzForceCovariant:1600} after contraction with \( \gamma^\mu \).
Answer
In terms of coordinates, the first order Taylor expansion of the action is
\begin{equation}\label{eqn:lorentzForceCovariant:180}
\begin{aligned}
S &\rightarrow S + \delta S \\
&= \int d\tau L( x^\alpha + \epsilon^\alpha, \dot{x}^\alpha + \dot{\epsilon}^\alpha) \\
&=
\int d\tau \lr{
L(x^\alpha, \dot{x}^\alpha) + \epsilon^\mu \PD{x^\mu}{L} + \dot{\epsilon}^\mu \PD{\dot{x}^\mu}{L}
}.
\end{aligned}
\end{equation}
As before, we integrate by parts to separate out a pure boundary term
\begin{equation}\label{eqn:lorentzForceCovariant:200}
\delta S =
\int d\tau \epsilon^\mu
\lr{
\PD{x^\mu}{L} – \frac{d}{d\tau} \PD{\dot{x}^\mu}{L}
}
+
\int d\tau \frac{d}{d\tau} \lr{
\epsilon^\mu \PD{\dot{x}^\mu}{L}
}.
\end{equation}
The boundary term is killed since \( \epsilon^\mu = 0 \) at the end points of the action integral. We conclude that extremization of the action (\( \delta S = 0 \), for all \( \epsilon^\mu \)) requires
\begin{equation}\label{eqn:lorentzForceCovariant:220}
\PD{x^\mu}{L} – \frac{d}{d\tau} \PD{\dot{x}^\mu}{L} = 0.
\end{equation}
Lorentz force equation.
Theorem 1.3: Lorentz force.
The relativistic Lagrangian for a charged particle is
\begin{equation}\label{eqn:lorentzForceCovariant:1640}
L = \inv{2} m v^2 + q A \cdot v/c.
\end{equation}
Application of the Euler-Lagrange equations to this Lagrangian yields the Lorentz-force equation
\begin{equation}\label{eqn:lorentzForceCovariant:1660}
\frac{dp}{d\tau} = q F \cdot v/c,
\end{equation}
where \( p = m v \) is the proper momentum, \( F \) is the Faraday bivector \( F = \grad \wedge A \), and \( c \) is the speed of light.
Start proof:
To make life easier, let’s take advantage of the linearity of the Lagrangian, and break it into the free particle Lagrangian \( L_0 = (1/2) m v^2 \) and a potential term \( L_1 = q A \cdot v/c \). For the free particle case we have
\begin{equation}\label{eqn:lorentzForceCovariant:240}
\begin{aligned}
\delta L_0
&= \grad L_0 – \frac{d}{d\tau} (\grad_v L_0) \\
&= – \frac{d}{d\tau} (m v) \\
&= – \frac{dp}{d\tau}.
\end{aligned}
\end{equation}
For the potential contribution we have
\begin{equation}\label{eqn:lorentzForceCovariant:260}
\begin{aligned}
\delta L_1
&= \grad L_1 – \frac{d}{d\tau} (\grad_v L_1) \\
&= \frac{q}{c} \lr{ \grad (A \cdot v) – \frac{d}{d\tau} \lr{ \grad_v (A \cdot v)} } \\
&= \frac{q}{c} \lr{ \grad (A \cdot v) – \frac{dA}{d\tau} }.
\end{aligned}
\end{equation}
The proper time derivative can be evaluated using the chain rule
\begin{equation}\label{eqn:lorentzForceCovariant:280}
\frac{dA}{d\tau}
=
\frac{\partial x^\mu}{\partial \tau} \partial_\mu A
= (v \cdot \grad) A.
\end{equation}
Putting all the pieces back together we have
\begin{equation}\label{eqn:lorentzForceCovariant:300}
\begin{aligned}
0
&= \delta L \\
&=
-\frac{dp}{d\tau} + \frac{q}{c} \lr{ \grad (A \cdot v) – (v \cdot \grad) A } \\
&=
-\frac{dp}{d\tau} + \frac{q}{c} \lr{ \grad \wedge A } \cdot v.
\end{aligned}
\end{equation}
End proof.
Problem: Gradient of a squared position vector.
Show that
\begin{equation*}
\grad (a \cdot x) = a,
\end{equation*}
and
\begin{equation*}
\grad x^2 = 2 x.
\end{equation*}
It should be clear that the same ideas can be used for the velocity gradient, where we obtain \( \grad_v (v^2) = 2 v \), and \( \grad_v (A \cdot v) = A \), as used in the derivation above.
Answer
The first identity follows easily by expansion in coordinates
\begin{equation}\label{eqn:lorentzForceCovariant:320}
\begin{aligned}
\grad (a \cdot x)
&=
\gamma^\mu \partial_\mu a_\alpha x^\alpha \\
&=
\gamma^\mu a_\alpha \delta_\mu^\alpha \\
&=
\gamma^\mu a_\mu \\
&=
a.
\end{aligned}
\end{equation}
The second identity follows by linearity of the gradient
\begin{equation}\label{eqn:lorentzForceCovariant:340}
\begin{aligned}
\grad x^2
&=
\grad (x \cdot x) \\
&=
\evalbar{\lr{\grad (x \cdot a)}}{a = x}
+
\evalbar{\lr{\grad (b \cdot x)}}{b = x} \\
&=
\evalbar{a}{a = x}
+
\evalbar{b}{b = x} \\
&=
2x.
\end{aligned}
\end{equation}
It is desirable to put this relativistic Lorentz force equation into the usual vector and tensor forms for comparison.
Theorem 1.4: Tensor form of the Lorentz force equation.
The tensor form of the Lorentz force equation is
\begin{equation}\label{eqn:lorentzForceCovariant:1620}
\frac{dp^\mu}{d\tau} = \frac{q}{c} F^{\mu\nu} v_\nu,
\end{equation}
where the antisymmetric Faraday tensor is defined as \( F^{\mu\nu} = \partial^\mu A^\nu – \partial^\nu A^\mu \).
Start proof:
We have only to dot both sides with \( \gamma^\mu \). On the left we have
\begin{equation}\label{eqn:lorentzForceCovariant:380}
\gamma^\mu \cdot \frac{dp}{d\tau}
=
\frac{dp^\mu}{d\tau}.
\end{equation}
On the right, we have
\begin{equation}\label{eqn:lorentzForceCovariant:400}
\begin{aligned}
\gamma^\mu \cdot \lr{ \frac{q}{c} F \cdot v }
&=
\frac{q}{c} (( \grad \wedge A ) \cdot v ) \cdot \gamma^\mu \\
&=
\frac{q}{c} ( \grad ( A \cdot v ) – (v \cdot \grad) A ) \cdot \gamma^\mu \\
&=
\frac{q}{c} \lr{ (\partial^\mu A^\nu) v_\nu – v_\nu \partial^\nu A^\mu } \\
&=
\frac{q}{c} F^{\mu\nu} v_\nu.
\end{aligned}
\end{equation}
End proof.
Problem: Tensor expansion of \(F\).
An alternate way to demonstrate \ref{eqn:lorentzForceCovariant:1620} is to first expand \( F = \grad \wedge A \) in terms of coordinates, an expansion that can be expressed in terms of a second rank tensor antisymmetric tensor \( F^{\mu\nu} \). Find that expansion, and re-evaluate the dot products of \ref{eqn:lorentzForceCovariant:400} using that.
Answer
\begin{equation}\label{eqn:lorentzForceCovariant:900}
\begin{aligned}
F &=
\grad \wedge A \\
&=
\lr{ \gamma_\mu \partial^\mu } \wedge \lr{ \gamma_\nu A^\nu } \\
&=
\lr{ \gamma_\mu \wedge \gamma_\nu } \partial^\mu A^\nu.
\end{aligned}
\end{equation}
To this we can use the usual tensor trick (add self to self, change indexes, and divide by two), to give
\begin{equation}\label{eqn:lorentzForceCovariant:920}
\begin{aligned}
F &=
\inv{2} \lr{
\lr{ \gamma_\mu \wedge \gamma_\nu } \partial^\mu A^\nu
+
\lr{ \gamma_\nu \wedge \gamma_\mu } \partial^\nu A^\mu
} \\
&=
\inv{2}
\lr{ \gamma_\mu \wedge \gamma_\nu } \lr{
\partial^\mu A^\nu
–
\partial^\nu A^\mu
},
\end{aligned}
\end{equation}
which is just
\begin{equation}\label{eqn:lorentzForceCovariant:940}
F =
\inv{2} \lr{ \gamma_\mu \wedge \gamma_\nu } F^{\mu\nu}.
\end{equation}
Now, let’s expand \( (F \cdot v) \cdot \gamma^\mu \) to compare to the earlier expansion in terms of \( \grad \) and \( A \).
\begin{equation}\label{eqn:lorentzForceCovariant:960}
\begin{aligned}
(F \cdot v) \cdot \gamma^\mu
&=
\inv{2}
F^{\alpha\nu}
\lr{ \lr{ \gamma_\alpha \wedge \gamma_\nu } \cdot \lr{ \gamma^\beta v_\beta } } \cdot \gamma^\mu \\
&=
\inv{2}
F^{\alpha\nu} v_\beta
\lr{
{\delta_\nu}^\beta {\gamma_\alpha}^\mu
–
{\delta_\alpha}^\beta {\gamma_\nu}^\mu
} \\
&=
\inv{2}
\lr{
F^{\mu\beta} v_\beta
–
F^{\beta\mu} v_\beta
} \\
&=
F^{\mu\nu} v_\nu.
\end{aligned}
\end{equation}
This alternate expansion illustrates some of the connectivity between the geometric algebra approach and the traditional tensor formalism.
Problem: Lorentz force direct tensor derivation.
Instead of using the geometric algebra form of the Lorentz force equation as a stepping stone, we may derive the tensor form from the Lagrangian directly, provided the Lagrangian is put into tensor form
\begin{equation*}
L = \inv{2} m v^\mu v_\mu + q A^\mu v_\mu /c.
\end{equation*}
Evaluate the Euler-Lagrange equations in coordinate form and compare to \ref{eqn:lorentzForceCovariant:1620}.
Answer
Let \( \delta_\mu L = \gamma_\mu \cdot \delta L \), so that we can write the Euler-Lagrange equations as
\begin{equation}\label{eqn:lorentzForceCovariant:460}
0 = \delta_\mu L = \PD{x^\mu}{L} – \frac{d}{d\tau} \PD{\dot{x}^\mu}{L}.
\end{equation}
Operating on the kinetic term of the Lagrangian, we have
\begin{equation}\label{eqn:lorentzForceCovariant:480}
\delta_\mu L_0 = – \frac{d}{d\tau} m v_\mu.
\end{equation}
For the potential term
\begin{equation}\label{eqn:lorentzForceCovariant:500}
\begin{aligned}
\delta_\mu L_1
&=
\frac{q}{c} \lr{
v_\nu \PD{x^\mu}{A^\nu} – \frac{d}{d\tau} A_\mu
} \\
&=
\frac{q}{c} \lr{
v_\nu \PD{x^\mu}{A^\nu} – \frac{dx_\alpha}{d\tau} \PD{x_\alpha}{ A_\mu }
} \\
&=
\frac{q}{c} v^\nu \lr{
\partial_\mu A_\nu – \partial_\nu A_\mu
} \\
&=
\frac{q}{c} v^\nu F_{\mu\nu}.
\end{aligned}
\end{equation}
Putting the pieces together gives
\begin{equation}\label{eqn:lorentzForceCovariant:520}
\frac{d}{d\tau} (m v_\mu) = \frac{q}{c} v^\nu F_{\mu\nu},
\end{equation}
which is identical\footnote{Some minor index raising and lowering gymnastics are required.} to the tensor form that we found by expanding the geometric algebra form of Maxwell’s equation in coordinates.
Theorem 1.5: Vector Lorentz force equation.
Relative to a fixed observer’s frame, the Lorentz force equation of \ref{eqn:lorentzForceCovariant:1660} splits into a spatial rate of change of momentum, and (timelike component) rate of change of energy, as follows
\begin{equation}\label{eqn:lorentzForceCovariant:1680}
\begin{aligned}
\ddt{(\gamma m \Bv)} &= q \lr{ \BE + \Bv \cross \BB } \\
\ddt{(\gamma m c^2)} &= q \Bv \cdot \BE,
\end{aligned}
\end{equation}
where \( F = \BE + I c \BB \), \( \gamma = 1/\sqrt{1 – \Bv^2/c^2 }\).
Start proof:
The first step is to eliminate the proper time dependencies in the Lorentz force equation. Consider first the coordinate representation of an arbitrary position four-vector \( x \)
\begin{equation}\label{eqn:lorentzForceCovariant:1140}
x = c t \gamma_0 + x^k \gamma_k.
\end{equation}
The corresponding four-vector velocity is
\begin{equation}\label{eqn:lorentzForceCovariant:1160}
v = \ddtau{x} = c \ddtau{t} \gamma_0 + \ddtau{t} \ddt{x^k} \gamma_k.
\end{equation}
By construction, \( v^2 = c^2 \) is a Lorentz invariant quantity (this is one of the relativistic postulates), so the LHS of \ref{eqn:lorentzForceCovariant:1160} must have the same square. That is
\begin{equation}\label{eqn:lorentzForceCovariant:1240}
c^2 = \lr{ \ddtau{t} }^2 \lr{ c^2 – \Bv^2 },
\end{equation}
where \( \Bv = v \wedge \gamma_0 \). This shows that we may make the identification
\begin{equation}\label{eqn:lorentzForceCovariant:1260}
\gamma = \ddtau{t} = \inv{1 – \Bv^2/c^2 },
\end{equation}
and
\begin{equation}\label{eqn:lorentzForceCovariant:1280}
\ddtau{} = \ddtau{t} \ddt{} = \gamma \ddt{}.
\end{equation}
We may now factor the four-velocity \( v \) into its spacetime split
\begin{equation}\label{eqn:lorentzForceCovariant:1300}
v = \gamma \lr{ c + \Bv } \gamma_0.
\end{equation}
In particular the LHS of the Lorentz force equation can be rewritten as
\begin{equation}\label{eqn:lorentzForceCovariant:1320}
\ddtau{p} = \gamma \ddt{}\lr{ \gamma \lr{ c + \Bv } } \gamma_0,
\end{equation}
and the RHS of the Lorentz force equation can be rewritten as
\begin{equation}\label{eqn:lorentzForceCovariant:1340}
\frac{q}{c} F \cdot v
=
\frac{\gamma q}{c} F \cdot \lr{ (c + \Bv) \gamma_0 }.
\end{equation}
Equating timelike and spacelike components leaves us
\begin{equation}\label{eqn:lorentzForceCovariant:1380}
\ddt{ (m \gamma c) } = \frac{q}{c} \lr{ F \cdot \lr{ (c + \Bv) \gamma_0 } } \cdot \gamma_0,
\end{equation}
\begin{equation}\label{eqn:lorentzForceCovariant:1400}
\ddt{ (m \gamma \Bv) } = \frac{q}{c} \lr{ F \cdot \lr{ (c + \Bv) \gamma_0 } } \wedge \gamma_0,
\end{equation}
Evaluating these products requires some care, but is an essentially manual process. The reader is encouraged to do so once, but the end result may also be obtained easily using software (see lorentzForce.nb in [2]). One finds
\begin{equation}\label{eqn:lorentzForceCovariant:1440}
F = \BE + I c \BB
=
E^1 \gamma_{10} +
+ E^2 \gamma_{20} +
+ E^3 \gamma_{30} +
– c B^1 \gamma_{23} +
– c B^2 \gamma_{31} +
– c B^3 \gamma_{12},
\end{equation}
\begin{equation}\label{eqn:lorentzForceCovariant:1460}
\frac{q}{c} \lr{ F \cdot \lr{ (c + \Bv) \gamma_0 } } \cdot \gamma_0
= \frac{q}{c} \BE \cdot \Bv,
\end{equation}
\begin{equation}\label{eqn:lorentzForceCovariant:1480}
\frac{q}{c} \lr{ F \cdot \lr{ (c + \Bv) \gamma_0 } } \wedge \gamma_0
= q \lr{ \BE + \Bv \cross \BB }.
\end{equation}
End proof.
Problem: Algebraic spacetime split of the Lorentz force equation.
Derive the results of \ref{eqn:lorentzForceCovariant:1440} through \ref{eqn:lorentzForceCovariant:1480} algebraically.
Problem: Spacetime split of the Lorentz force tensor equation.
Show that \ref{eqn:lorentzForceCovariant:1680} also follows from the tensor form of the Lorentz force equation (\ref{eqn:lorentzForceCovariant:1620}) provided we identify
\begin{equation}\label{eqn:lorentzForceCovariant:1500}
F^{k0} = E^k,
\end{equation}
and
\begin{equation}\label{eqn:lorentzForceCovariant:1520}
F^{rs} = -\epsilon^{rst} B^t.
\end{equation}
Also verify that the identifications of \ref{eqn:lorentzForceCovariant:1500} and \ref{eqn:lorentzForceCovariant:1520} is consistent with the geometric algebra Faraday bivector \( F = \BE + I c \BB \), and the associated coordinate expansion of the field \( F = (1/2) (\gamma_\mu \wedge \gamma_\nu) F^{\mu\nu} \).
References
[1] C. Doran and A.N. Lasenby. Geometric algebra for physicists. Cambridge University Press New York, Cambridge, UK, 1st edition, 2003.
[2] Peeter Joot. Mathematica modules for Geometric Algebra’s GA(2,0), GA(3,0), and GA(1,3), 2017. URL https://github.com/peeterjoot/gapauli. [Online; accessed 24-Oct-2020].
Like this:
Like Loading...