Notes.
Due to limitations in the MathJax-Latex package, all the oriented integrals in this blog post should be interpreted as having a clockwise orientation. [See the PDF version of this post for more sophisticated formatting.]
Guts.
Given a two dimensional generating vector space, there are two instances of the fundamental theorem for multivector integration
\begin{equation}\label{eqn:unpackingFundamentalTheorem:20}
\int_S F d\Bx \lrpartial G = \evalbar{F G}{\Delta S},
\end{equation}
and
\begin{equation}\label{eqn:unpackingFundamentalTheorem:40}
\int_S F d^2\Bx \lrpartial G = \oint_{\partial S} F d\Bx G.
\end{equation}
The first case is trivial. Given a parameterizated curve \( x = x(u) \), it just states
\begin{equation}\label{eqn:unpackingFundamentalTheorem:60}
\int_{u(0)}^{u(1)} du \PD{u}{}\lr{FG} = F(u(1))G(u(1)) – F(u(0))G(u(0)),
\end{equation}
for all multivectors \( F, G\), regardless of the signature of the underlying space.
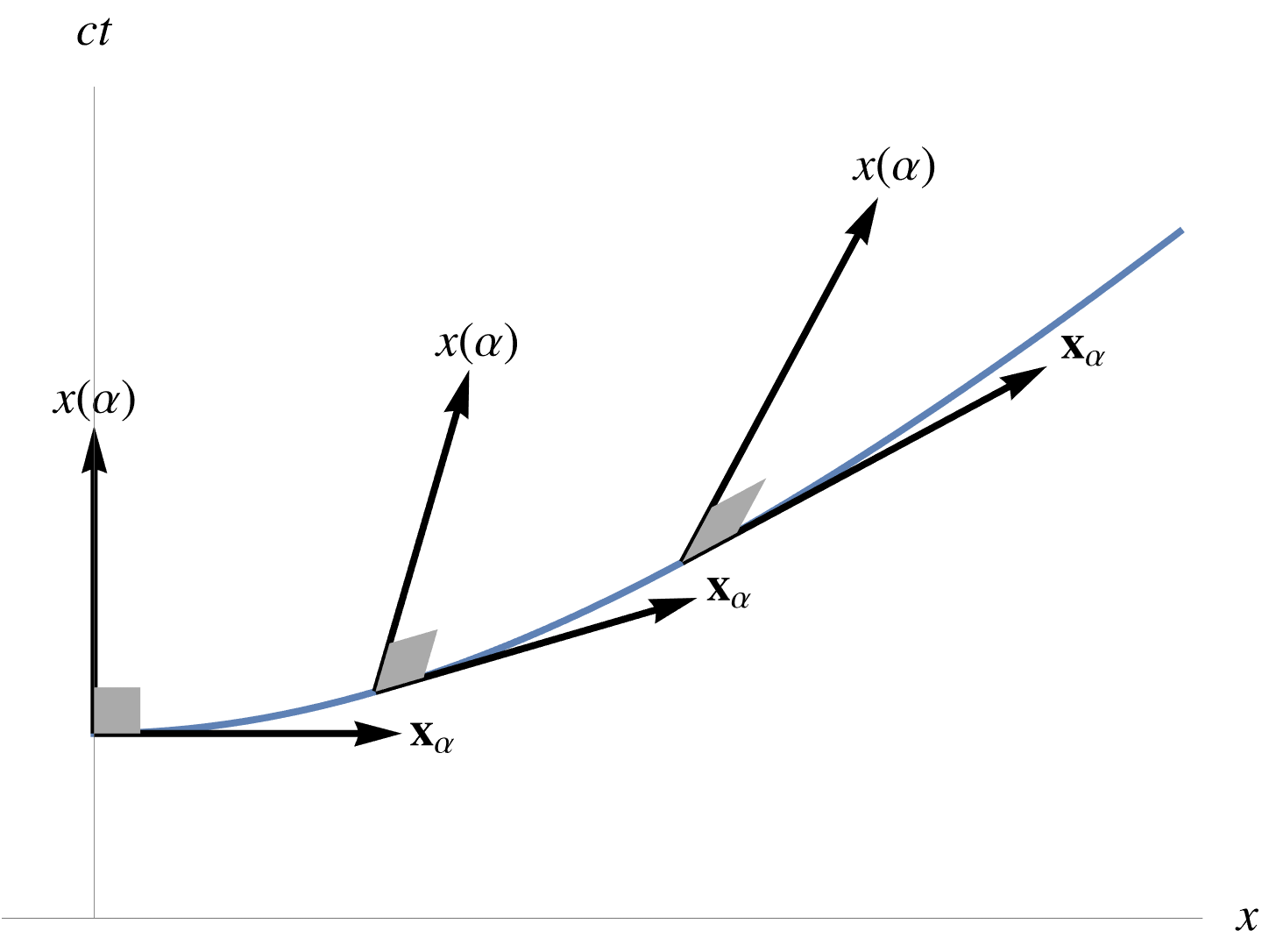
The surface integral is more interesting. Let’s first look at the area element for this surface integral, which is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:80}
d^2 \Bx = d\Bx_u \wedge d \Bx_v.
\end{equation}
Geometrically, this has the area of the parallelogram spanned by \( d\Bx_u \) and \( d\Bx_v \), but weighted by the pseudoscalar of the space. This is explored algebraically in the following problem and illustrated in fig. 1.
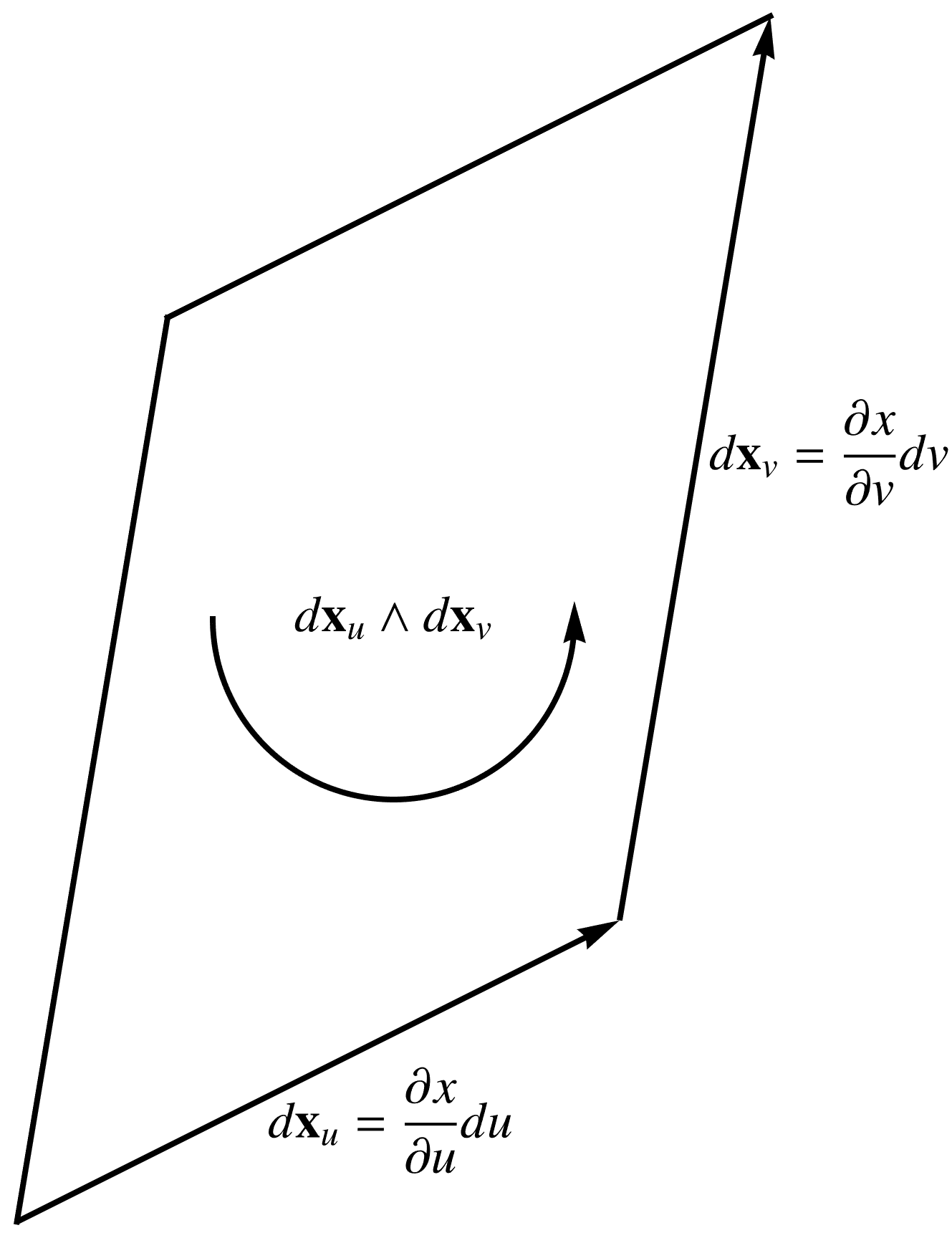
fig. 1. 2D vector space and area element.
Problem: Expansion of 2D area bivector.
Let \( \setlr{e_1, e_2} \) be an orthonormal basis for a two dimensional space, with reciprocal frame \( \setlr{e^1, e^2} \). Expand the area bivector \( d^2 \Bx \) in coordinates relating the bivector to the Jacobian and the pseudoscalar.
Answer
With parameterization \( x = x(u,v) = x^\alpha e_\alpha = x_\alpha e^\alpha \), we have
\begin{equation}\label{eqn:unpackingFundamentalTheorem:120}
\Bx_u \wedge \Bx_v
=
\lr{ \PD{u}{x^\alpha} e_\alpha } \wedge
\lr{ \PD{v}{x^\beta} e_\beta }
=
\PD{u}{x^\alpha}
\PD{v}{x^\beta}
e_\alpha
e_\beta
=
\PD{(u,v)}{(x^1,x^2)} e_1 e_2,
\end{equation}
or
\begin{equation}\label{eqn:unpackingFundamentalTheorem:160}
\Bx_u \wedge \Bx_v
=
\lr{ \PD{u}{x_\alpha} e^\alpha } \wedge
\lr{ \PD{v}{x_\beta} e^\beta }
=
\PD{u}{x_\alpha}
\PD{v}{x_\beta}
e^\alpha
e^\beta
=
\PD{(u,v)}{(x_1,x_2)} e^1 e^2.
\end{equation}
The upper and lower index pseudoscalars are related by
\begin{equation}\label{eqn:unpackingFundamentalTheorem:180}
e^1 e^2 e_1 e_2 =
-e^1 e^2 e_2 e_1 =
-1,
\end{equation}
so with \( I = e_1 e_2 \),
\begin{equation}\label{eqn:unpackingFundamentalTheorem:200}
e^1 e^2 = -I^{-1},
\end{equation}
leaving us with
\begin{equation}\label{eqn:unpackingFundamentalTheorem:140}
d^2 \Bx
= \PD{(u,v)}{(x^1,x^2)} du dv\, I
= -\PD{(u,v)}{(x_1,x_2)} du dv\, I^{-1}.
\end{equation}
We see that the area bivector is proportional to either the upper or lower index Jacobian and to the pseudoscalar for the space.
We may write the fundamental theorem for a 2D space as
\begin{equation}\label{eqn:unpackingFundamentalTheorem:680}
\int_S du dv \, \PD{(u,v)}{(x^1,x^2)} F I \lrgrad G = \oint_{\partial S} F d\Bx G,
\end{equation}
where we have dispensed with the vector derivative and use the gradient instead, since they are identical in a two parameter two dimensional space. Of course, unless we are using \( x^1, x^2 \) as our parameterization, we still want the curvilinear representation of the gradient \( \grad = \Bx^u \PDi{u}{} + \Bx^v \PDi{v}{} \).
Problem: Standard basis expansion of fundamental surface relation.
For a parameterization \( x = x^1 e_1 + x^2 e_2 \), where \( \setlr{ e_1, e_2 } \) is a standard (orthogonal) basis, expand the fundamental theorem for surface integrals for the single sided \( F = 1 \) case. Consider functions \( G \) of each grade (scalar, vector, bivector.)
Answer
From \ref{eqn:unpackingFundamentalTheorem:140} we see that the fundamental theorem takes the form
\begin{equation}\label{eqn:unpackingFundamentalTheorem:220}
\int_S dx^1 dx^2\, F I \lrgrad G = \oint_{\partial S} F d\Bx G.
\end{equation}
In a Euclidean space, the operator \( I \lrgrad \), is a \( \pi/2 \) rotation of the gradient, but has a rotated like structure in all metrics:
\begin{equation}\label{eqn:unpackingFundamentalTheorem:240}
I \grad
=
e_1 e_2 \lr{ e^1 \partial_1 + e^2 \partial_2 }
=
-e_2 \partial_1 + e_1 \partial_2.
\end{equation}
- \( F = 1 \) and \( G \in \bigwedge^0 \) or \( G \in \bigwedge^2 \). For \( F = 1 \) and scalar or bivector \( G \) we have
\begin{equation}\label{eqn:unpackingFundamentalTheorem:260}
\int_S dx^1 dx^2\, \lr{ -e_2 \partial_1 + e_1 \partial_2 } G = \oint_{\partial S} d\Bx G,
\end{equation}
where, for \( x^1 \in [x^1(0),x^1(1)] \) and \( x^2 \in [x^2(0),x^2(1)] \), the RHS written explicitly is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:280}
\oint_{\partial S} d\Bx G
=
\int dx^1 e_1
\lr{ G(x^1, x^2(1)) – G(x^1, x^2(0)) }
– dx^2 e_2
\lr{ G(x^1(1),x^2) – G(x^1(0), x^2) }.
\end{equation}
This is sketched in fig. 2. Since a 2D bivector \( G \) can be written as \( G = I g \), where \( g \) is a scalar, we may write the pseudoscalar case as
\begin{equation}\label{eqn:unpackingFundamentalTheorem:300}
\int_S dx^1 dx^2\, \lr{ -e_2 \partial_1 + e_1 \partial_2 } g = \oint_{\partial S} d\Bx g,
\end{equation}
after right multiplying both sides with \( I^{-1} \). Algebraically the scalar and pseudoscalar cases can be thought of as identical scalar relationships. - \( F = 1, G \in \bigwedge^1 \). For \( F = 1 \) and vector \( G \) the 2D fundamental theorem for surfaces can be split into scalar
\begin{equation}\label{eqn:unpackingFundamentalTheorem:320}
\int_S dx^1 dx^2\, \lr{ -e_2 \partial_1 + e_1 \partial_2 } \cdot G = \oint_{\partial S} d\Bx \cdot G,
\end{equation}
and bivector relations
\begin{equation}\label{eqn:unpackingFundamentalTheorem:340}
\int_S dx^1 dx^2\, \lr{ -e_2 \partial_1 + e_1 \partial_2 } \wedge G = \oint_{\partial S} d\Bx \wedge G.
\end{equation}
To expand \ref{eqn:unpackingFundamentalTheorem:320}, let
\begin{equation}\label{eqn:unpackingFundamentalTheorem:360}
G = g_1 e^1 + g_2 e^2,
\end{equation}
for which
\begin{equation}\label{eqn:unpackingFundamentalTheorem:380}
\lr{ -e_2 \partial_1 + e_1 \partial_2 } \cdot G
=
\lr{ -e_2 \partial_1 + e_1 \partial_2 } \cdot
\lr{ g_1 e^1 + g_2 e^2 }
=
\partial_2 g_1 – \partial_1 g_2,
\end{equation}
and
\begin{equation}\label{eqn:unpackingFundamentalTheorem:400}
d\Bx \cdot G
=
\lr{ dx^1 e_1 – dx^2 e_2 } \cdot \lr{ g_1 e^1 + g_2 e^2 }
=
dx^1 g_1 – dx^2 g_2,
\end{equation}
so \ref{eqn:unpackingFundamentalTheorem:320} expands to
\begin{equation}\label{eqn:unpackingFundamentalTheorem:500}
\int_S dx^1 dx^2\, \lr{ \partial_2 g_1 – \partial_1 g_2 }
=
\int
\evalbar{dx^1 g_1}{\Delta x^2} – \evalbar{ dx^2 g_2 }{\Delta x^1}.
\end{equation}
This coordinate expansion illustrates how the pseudoscalar nature of the area element results in a duality transformation, as we end up with a curl like operation on the LHS, despite the dot product nature of the decomposition that we used. That can also be seen directly for vector \( G \), since
\begin{equation}\label{eqn:unpackingFundamentalTheorem:560}
dA (I \grad) \cdot G
=
dA \gpgradezero{ I \grad G }
=
dA I \lr{ \grad \wedge G },
\end{equation}
since the scalar selection of \( I \lr{ \grad \cdot G } \) is zero.In the grade-2 relation \ref{eqn:unpackingFundamentalTheorem:340}, we expect a pseudoscalar cancellation on both sides, leaving a scalar (divergence-like) relationship. This time, we use upper index coordinates for the vector \( G \), letting
\begin{equation}\label{eqn:unpackingFundamentalTheorem:440}
G = g^1 e_1 + g^2 e_2,
\end{equation}
so
\begin{equation}\label{eqn:unpackingFundamentalTheorem:460}
\lr{ -e_2 \partial_1 + e_1 \partial_2 } \wedge G
=
\lr{ -e_2 \partial_1 + e_1 \partial_2 } \wedge G
\lr{ g^1 e_1 + g^2 e_2 }
=
e_1 e_2 \lr{ \partial_1 g^1 + \partial_2 g^2 },
\end{equation}
and
\begin{equation}\label{eqn:unpackingFundamentalTheorem:480}
d\Bx \wedge G
=
\lr{ dx^1 e_1 – dx^2 e_2 } \wedge
\lr{ g^1 e_1 + g^2 e_2 }
=
e_1 e_2 \lr{ dx^1 g^2 + dx^2 g^1 }.
\end{equation}
So \ref{eqn:unpackingFundamentalTheorem:340}, after multiplication of both sides by \( I^{-1} \), is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:520}
\int_S dx^1 dx^2\,
\lr{ \partial_1 g^1 + \partial_2 g^2 }
=
\int
\evalbar{dx^1 g^2}{\Delta x^2} + \evalbar{dx^2 g^1 }{\Delta x^1}.
\end{equation}
As before, we’ve implicitly performed a duality transformation, and end up with a divergence operation. That can be seen directly without coordinate expansion, by rewriting the wedge as a grade two selection, and expanding the gradient action on the vector \( G \), as follows
\begin{equation}\label{eqn:unpackingFundamentalTheorem:580}
dA (I \grad) \wedge G
=
dA \gpgradetwo{ I \grad G }
=
dA I \lr{ \grad \cdot G },
\end{equation}
since \( I \lr{ \grad \wedge G } \) has only a scalar component.
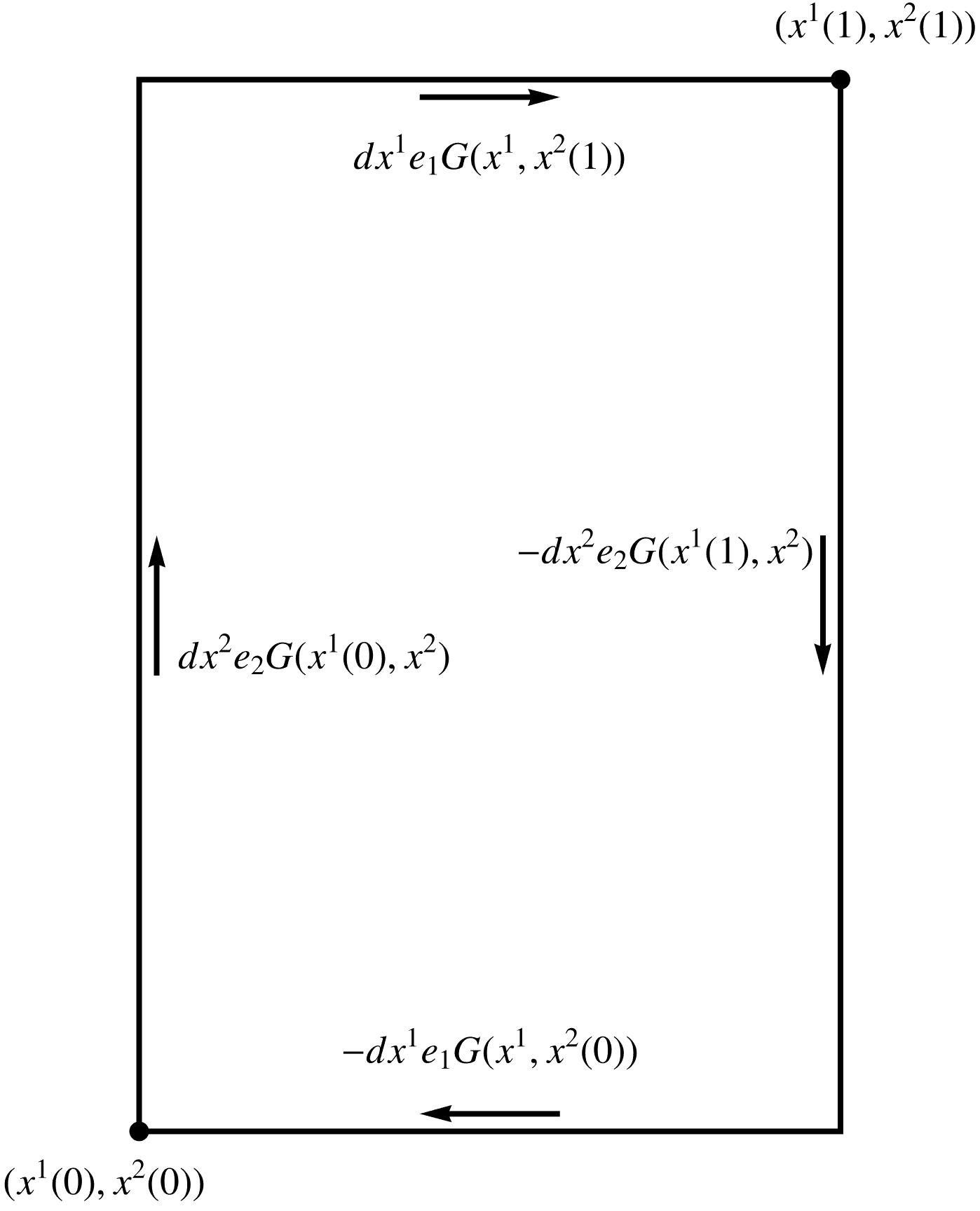
fig. 2. Line integral around rectangular boundary.
Theorem 1.1: Green’s theorem [1].
\begin{equation*}
\int dx dy \lr{ \PD{y}{P} – \PD{x}{Q} } = \oint P dx + Q dy.
\end{equation*}
Problem: Relationship to Green’s theorem.
If the space is Euclidean, show that \ref{eqn:unpackingFundamentalTheorem:500} and \ref{eqn:unpackingFundamentalTheorem:520} are both instances of Green’s theorem with suitable choices of \( P \) and \( Q \).
Answer
I will omit the subtleties related to general regions and consider just the case of an infinitesimal square region.
Start proof:
Let’s start with \ref{eqn:unpackingFundamentalTheorem:500}, with \( g_1 = P \) and \( g_2 = Q \), and \( x^1 = x, x^2 = y \), the RHS is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:600}
\int dx dy \lr{ \PD{y}{P} – \PD{x}{Q} }.
\end{equation}
On the RHS we have
\begin{equation}\label{eqn:unpackingFundamentalTheorem:620}
\int \evalbar{dx P}{\Delta y} – \evalbar{ dy Q }{\Delta x}
=
\int dx \lr{ P(x, y_1) – P(x, y_0) } – \int dy \lr{ Q(x_1, y) – Q(x_0, y) }.
\end{equation}
This pair of integrals is plotted in fig. 3, from which we see that \ref{eqn:unpackingFundamentalTheorem:620} can be expressed as the line integral, leaving us with
\begin{equation}\label{eqn:unpackingFundamentalTheorem:640}
\int dx dy \lr{ \PD{y}{P} – \PD{x}{Q} }
=
\oint dx P + dy Q,
\end{equation}
which is Green’s theorem over the infinitesimal square integration region.
For the equivalence of \ref{eqn:unpackingFundamentalTheorem:520} to Green’s theorem, let \( g^2 = P \), and \( g^1 = -Q \). Plugging into the LHS, we find the Green’s theorem integrand. On the RHS, the integrand expands to
\begin{equation}\label{eqn:unpackingFundamentalTheorem:660}
\evalbar{dx g^2}{\Delta y} + \evalbar{dy g^1 }{\Delta x}
=
dx \lr{ P(x,y_1) – P(x, y_0)}
+
dy \lr{ -Q(x_1, y) + Q(x_0, y)},
\end{equation}
which is exactly what we found in \ref{eqn:unpackingFundamentalTheorem:620}.
End proof.
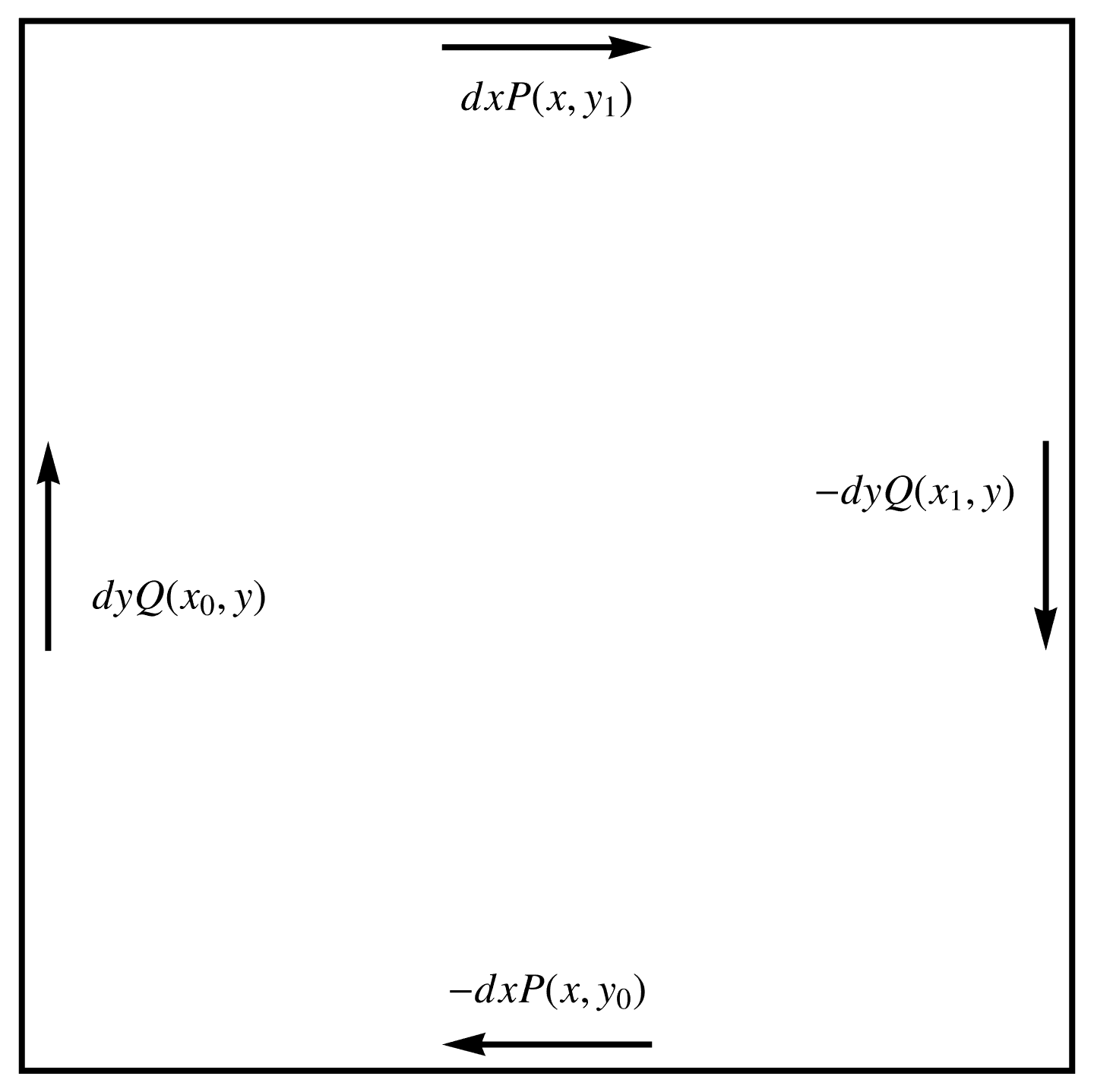
fig. 3. Path for Green’s theorem.
We may also relate multivector gradient integrals in 2D to the normal integral around the boundary of the bounding curve. That relationship is as follows.
Theorem 1.2: 2D gradient integrals.
\begin{aligned}
\int J du dv \rgrad G &= \oint I^{-1} d\Bx G = \int J \lr{ \Bx^v du + \Bx^u dv } G \\
\int J du dv F \lgrad &= \oint F I^{-1} d\Bx = \int J F \lr{ \Bx^v du + \Bx^u dv },
\end{aligned}
\end{equation*}
where \( J = \partial(x^1, x^2)/\partial(u,v) \) is the Jacobian of the parameterization \( x = x(u,v) \). In terms of the coordinates \( x^1, x^2 \), this reduces to
\begin{equation*}
\begin{aligned}
\int dx^1 dx^2 \rgrad G &= \oint I^{-1} d\Bx G = \int \lr{ e^2 dx^1 + e^1 dx^2 } G \\
\int dx^1 dx^2 F \lgrad &= \oint G I^{-1} d\Bx = \int F \lr{ e^2 dx^1 + e^1 dx^2 }.
\end{aligned}
\end{equation*}
The vector \( I^{-1} d\Bx \) is orthogonal to the tangent vector along the boundary, and for Euclidean spaces it can be identified as the outwards normal.
Start proof:
Respectively setting \( F = 1 \), and \( G = 1\) in \ref{eqn:unpackingFundamentalTheorem:680}, we have
\begin{equation}\label{eqn:unpackingFundamentalTheorem:940}
\int I^{-1} d^2 \Bx \rgrad G = \oint I^{-1} d\Bx G,
\end{equation}
and
\begin{equation}\label{eqn:unpackingFundamentalTheorem:960}
\int F d^2 \Bx \lgrad I^{-1} = \oint F d\Bx I^{-1}.
\end{equation}
Starting with \ref{eqn:unpackingFundamentalTheorem:940} we find
\begin{equation}\label{eqn:unpackingFundamentalTheorem:700}
\int I^{-1} J du dv I \rgrad G = \oint d\Bx G,
\end{equation}
to find \( \int dx^1 dx^2 \rgrad G = \oint I^{-1} d\Bx G \), as desireed. In terms of a parameterization \( x = x(u,v) \), the pseudoscalar for the space is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:720}
I = \frac{\Bx_u \wedge \Bx_v}{J},
\end{equation}
so
\begin{equation}\label{eqn:unpackingFundamentalTheorem:740}
I^{-1} = \frac{J}{\Bx_u \wedge \Bx_v}.
\end{equation}
Also note that \( \lr{\Bx_u \wedge \Bx_v}^{-1} = \Bx^v \wedge \Bx^u \), so
\begin{equation}\label{eqn:unpackingFundamentalTheorem:760}
I^{-1} = J \lr{ \Bx^v \wedge \Bx^u },
\end{equation}
and
\begin{equation}\label{eqn:unpackingFundamentalTheorem:780}
I^{-1} d\Bx
= I^{-1} \cdot d\Bx
= J \lr{ \Bx^v \wedge \Bx^u } \cdot \lr{ \Bx_u du – \Bx_v dv }
= J \lr{ \Bx^v du + \Bx^u dv },
\end{equation}
so the right acting gradient integral is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:800}
\int J du dv \grad G =
\int
\evalbar{J \Bx^v G}{\Delta v} du + \evalbar{J \Bx^u G dv}{\Delta u},
\end{equation}
which we write in abbreviated form as \( \int J \lr{ \Bx^v du + \Bx^u dv} G \).
For the \( G = 1 \) case, from \ref{eqn:unpackingFundamentalTheorem:960} we find
\begin{equation}\label{eqn:unpackingFundamentalTheorem:820}
\int J du dv F I \lgrad I^{-1} = \oint F d\Bx I^{-1}.
\end{equation}
However, in a 2D space, regardless of metric, we have \( I a = – a I \) for any vector \( a \) (i.e. \( \grad \) or \( d\Bx\)), so we may commute the outer pseudoscalars in
\begin{equation}\label{eqn:unpackingFundamentalTheorem:840}
\int J du dv F I \lgrad I^{-1} = \oint F d\Bx I^{-1},
\end{equation}
so
\begin{equation}\label{eqn:unpackingFundamentalTheorem:850}
-\int J du dv F I I^{-1} \lgrad = -\oint F I^{-1} d\Bx.
\end{equation}
After cancelling the negative sign on both sides, we have the claimed result.
To see that \( I a \), for any vector \( a \) is normal to \( a \), we can compute the dot product
\begin{equation}\label{eqn:unpackingFundamentalTheorem:860}
\lr{ I a } \cdot a
=
\gpgradezero{ I a a }
=
a^2 \gpgradezero{ I }
= 0,
\end{equation}
since the scalar selection of a bivector is zero. Since \( I^{-1} = \pm I \), the same argument shows that \( I^{-1} d\Bx \) must be orthogonal to \( d\Bx \).
End proof.
Let’s look at the geometry of the normal \( I^{-1} \Bx \) in a couple 2D vector spaces. We use an integration volume of a unit square to simplify the boundary term expressions.
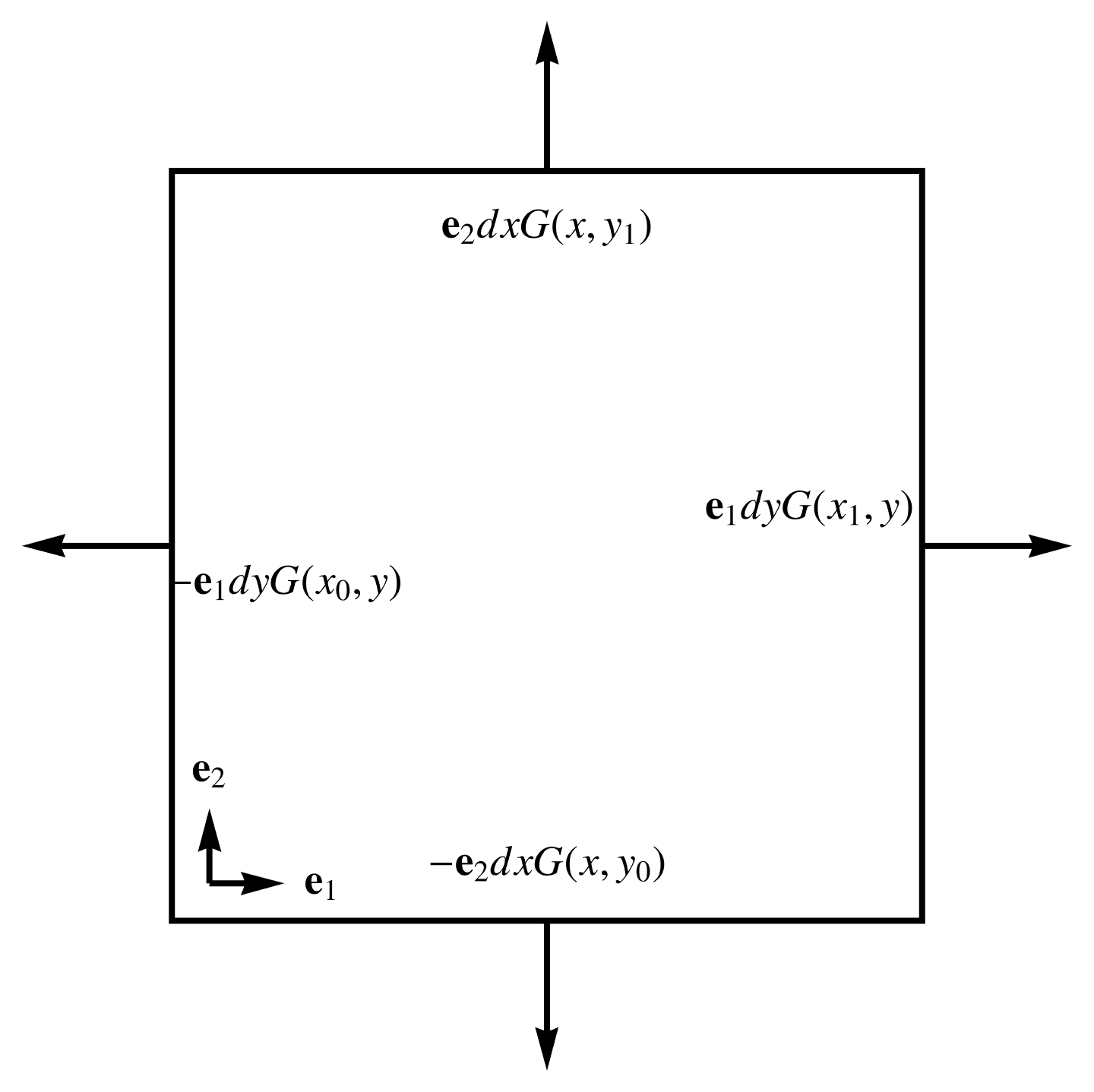
- Euclidean: With a parameterization \( x(u,v) = u\Be_1 + v \Be_2 \), and Euclidean basis vectors \( (\Be_1)^2 = (\Be_2)^2 = 1 \), the fundamental theorem integrated over the rectangle \( [x_0,x_1] \times [y_0,y_1] \) is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:880}
\int dx dy \grad G =
\int
\Be_2 \lr{ G(x,y_1) – G(x,y_0) } dx +
\Be_1 \lr{ G(x_1,y) – G(x_0,y) } dy,
\end{equation}
Each of the terms in the integrand above are illustrated in fig. 4, and we see that this is a path integral weighted by the outwards normal.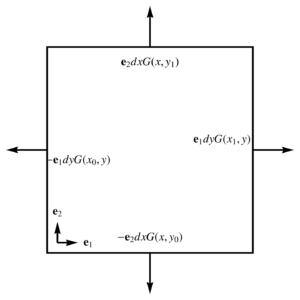
fig. 4. Outwards oriented normal for Euclidean space.
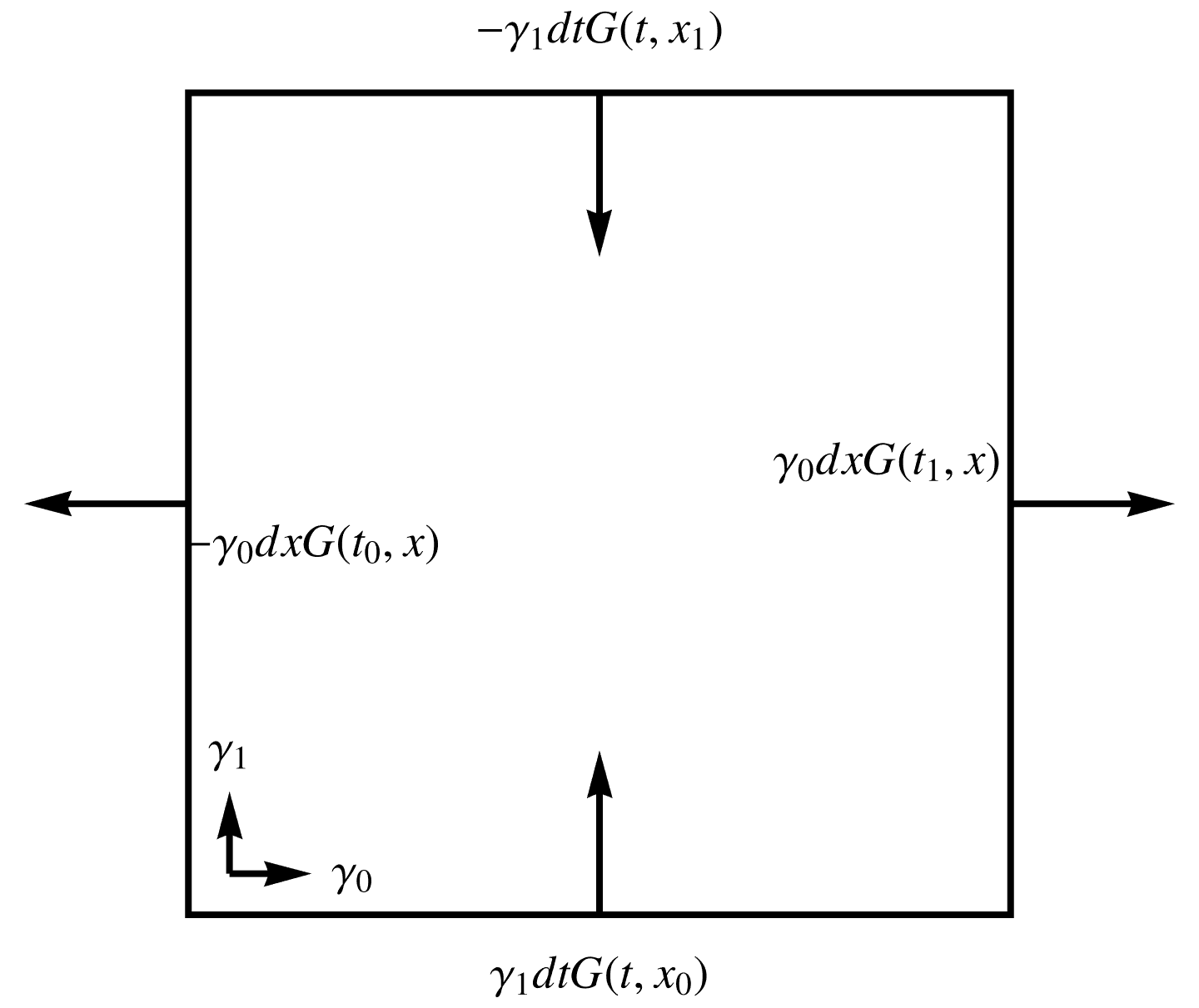
- Spacetime: Let \( x(u,v) = u \gamma_0 + v \gamma_1 \), where \( (\gamma_0)^2 = -(\gamma_1)^2 = 1 \). With \( u = t, v = x \), the gradient integral over a \([t_0,t_1] \times [x_0,x_1]\) of spacetime is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:900}
\begin{aligned}
\int dt dx \grad G
&=
\int
\gamma^1 dt \lr{ G(t, x_1) – G(t, x_0) }
+
\gamma^0 dx \lr{ G(t_1, x) – G(t_1, x) } \\
&=
\int
\gamma_1 dt \lr{ -G(t, x_1) + G(t, x_0) }
+
\gamma_0 dx \lr{ G(t_1, x) – G(t_1, x) }
.
\end{aligned}
\end{equation}
With \( t \) plotted along the horizontal axis, and \( x \) along the vertical, each of the terms of this integrand is illustrated graphically in fig. 5. For this mixed signature space, there is no longer any good geometrical characterization of the normal.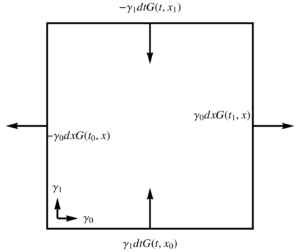
fig. 5. Orientation of the boundary normal for a spacetime basis.
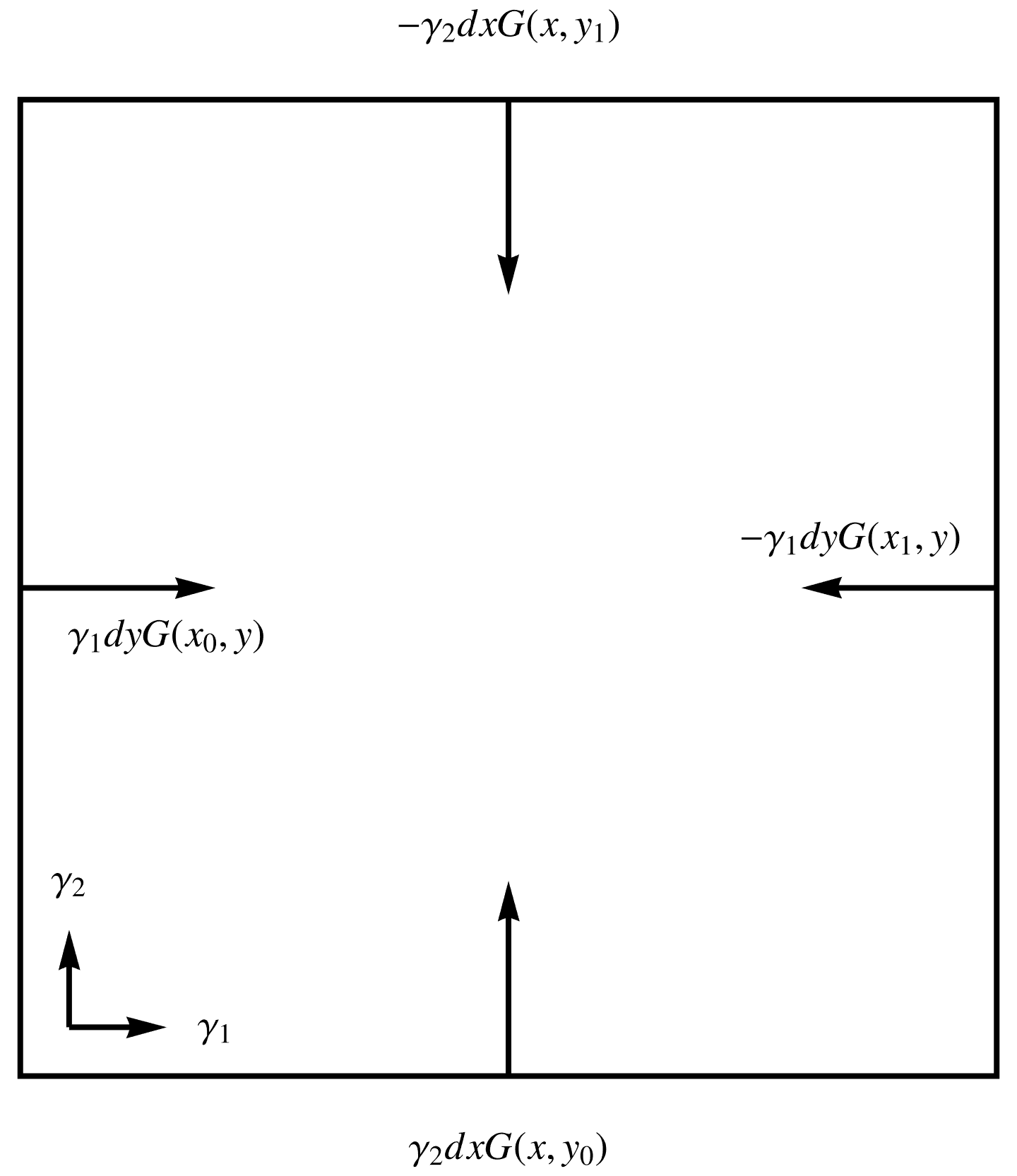
- Spacelike:
Let \( x(u,v) = u \gamma_1 + v \gamma_2 \), where \( (\gamma_1)^2 = (\gamma_2)^2 = -1 \). With \( u = x, v = y \), the gradient integral over a \([x_0,x_1] \times [y_0,y_1]\) of this space is
\begin{equation}\label{eqn:unpackingFundamentalTheorem:920}
\begin{aligned}
\int dx dy \grad G
&=
\int
\gamma^2 dx \lr{ G(x, y_1) – G(x, y_0) }
+
\gamma^1 dy \lr{ G(x_1, y) – G(x_1, y) } \\
&=
\int
\gamma_2 dx \lr{ -G(x, y_1) + G(x, y_0) }
+
\gamma_1 dy \lr{ -G(x_1, y) + G(x_1, y) }
.
\end{aligned}
\end{equation}
Referring to fig. 6. where the elements of the integrand are illustrated, we see that the normal \( I^{-1} d\Bx \) for the boundary of this region can be characterized as inwards.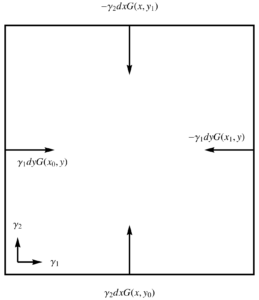
fig. 6. Inwards oriented normal for a Dirac spacelike basis.
References
[1] S.L. Salas and E. Hille. Calculus: one and several variables. Wiley New York, 1990.